
資安設定導致 Google 無法索引網站,這2個地方可看到 http 403 狀態碼
遇到一個神秘的網站,網站可以正常瀏覽連線,但在 Google 搜尋不到?
要先釐清是頁面根本沒有被索引,
還是只是在某個關鍵字排名很後面而已?
先做一些基本的檢查。
網站在 Google 完全搜尋不到?
- 先用
site:指令查一下,網站上線好幾年,而且都有外部連結,結果還真的一頁都沒被索引。這肯定有些問題。 - 檢查 Google Search Console 涵蓋範圍報表,有效頁面 0 個,都在「排除原因:檢索異常」。
- robots.txt 沒有異常的阻擋索引設定,只有放上後台網址。如果有駭客想知道管理後台登入路徑的,還可以從 robots.txt 查,很貼心。
- 頁面上沒加 meta noindex,所以頁面本身沒有阻擋索引
- 建立一個最簡單的 html 檔案丟在根目錄,Google Search Console 一樣只有很籠統的「網頁擷取狀態:失敗」,所以不是網站或程式有些 redirect 或 router 設定有誤。
- 把網址丟到 Google Search Console 去測,只有很籠統的「網頁擷取狀態:失敗」
- Search console 的專人介入處理裡面沒有資訊,應該沒有被官方封鎖。
嗯…該不會伺服器直接把外部連進來的 Google bot 擋掉了吧?
主機資安設定,導致爬蟲無法索引嗎?
這網站的伺服器不是一般公有雲/虛擬共享主機或 IDC 的公司在代管,而是由單位內部的網管 IT 專人管理,但是網管 IT 人員完全否定我們這種網頁設計慘業低階工人的推測(公司小,大家都沒有什麼顯赫的 title,真是對不起),什麼主機設定導致 SEO 問題?
網管也沒有美國時間去查 log,並依照驗證 Googlebot 去檢查是不是他把 Google 爬蟲擋掉了,
這的確非常的大公司:
– 工作內容就負責主機能正常運作,其他 SEO 什麼不是他管的。
– 資安就是寧可錯殺一百,不可漏放一個,聽信外包廠商的建議動了設定,如果出事了,外面廠商要賠嗎?
所以我們這些可憐的末端使用者得先想辦法證明:網站無法被 Google 索引,真的是主機資安的設定導致。
於是除了 Google Search Console,又試了幾個用來擷取網站內容的相關 Google 工具,把網址貼上去看看:
– 複合式搜尋結果測試 無法連線
– 行動裝置相容性測試 無法連線
– 安全瀏覽網站狀態
– Robots.txt 測試工具 神奇的是…顯示連線正常
– Google Ads,測試建立一則廣告,用問題網站當廣告到達網址,一樣是得到網站無法連線的訊息
幸好還是有兩個明燈

如上圖,從 PageSpeed Insights 可以得到 403 error。
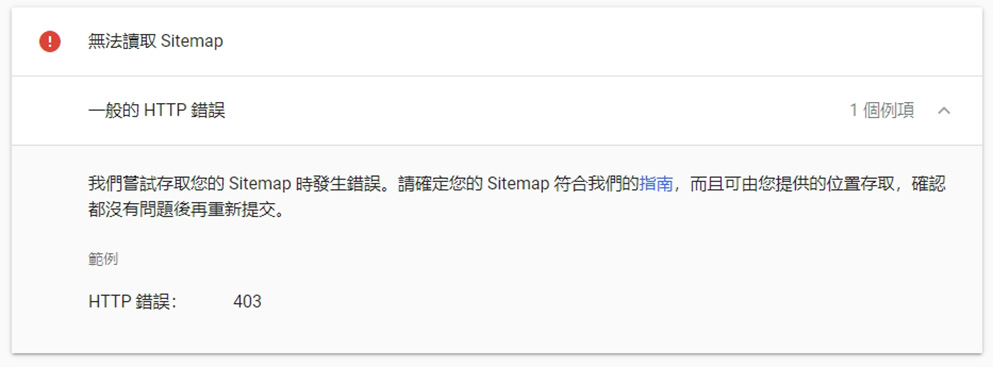
如上圖,在 Google Search console 裡面的 sitemap 提交工具,一樣可以得到 403 error。
這下終於比較有證據,證明可能是伺服器的 WAF 還是甚麼設定,讓 Google 的爬蟲無法正常索引了吧!
最後經由網管人員的調整,網站終於又開始在 Google 的自然搜尋排序中出現了,可喜可賀。
還有哪些站台設定,可能導致網站無法被 Google 索引到?
本例中是站台不知道哪邊的資安設定有問題,而導致網站無法被 Google 搜尋引擎的爬蟲存取,那再列幾個可能影響搜尋引擎爬蟲的站台設定。
1.用很舊版的 WordPress 做的網站,系統自動自發幫忙建立的 robots.txt 會阻擋 /wp-includes/ 或 /wp-content/ 等一些資料夾的內容,所以轉譯器抓到的網頁就會沒有樣式、沒有圖片,
(參考資料:How to Write a Robots.txt File…It’s an Art! (WordPress Focus)),因為顯示一個正常網頁的一些檔案被擋了,甚至站長會收到「網站有行動裝置可用性問題」之類的通知信件,就因為網頁在爬蟲機器人眼中無法正常顯示。
2.網站有設定遇到無效的網址就自動轉向到首頁(404->301),這設定很稀鬆平常,照片圖檔或商品頁面刪掉了,打網址進來當然就看不到,就跳轉回首頁讓訪客看最新的內容。
但是如果網站剛好沒放 robots.txt,搜尋引擎來爬網頁時先檢查 robots.txt,也會觸動這個(404->301)的情況,發現不只網站半頁都無法被正常索引到,連 Sitemap 都無法提交。Google Search Console 檢測網頁時出現的訊息也是很鬼打牆「索引建立要求遭拒」「一般的HTTP錯誤」「無法讀取sitemap」「我們嘗試存取您的sitemap時發生錯誤」,結果 robots.txt 放上去就正常了,所以有這種 404 自動轉回首頁機制的,robots.txt 一定要放。
順帶一提,無效網址轉回首頁這作法看似在 UX 很合理,但是因為現在常常有不明的爬蟲整天在亂 try 網站、猜測檔案重要程式的路徑,這種無效路徑自動轉回首頁的作法,反而無意間提高伺服器資源的消耗,尤其是首頁放很多複雜的程式的網站。
罄竹難書的歷史遺毒
話說這個神奇的網站不只 Google 找不到,
後來恢復正常之後,多逛了幾下,網站還真是罄竹難書,充滿各種歷史遺毒,有些特色正是搜尋引擎爬蟲檢索資料的大敵:
1.每一個產品單頁、產品清單頁的網頁 title 名稱,描述內容都一模一樣
雖然這個沒啥大不了的,反正現在 Google 搜尋引擎很聰明,就算有指定 title, meta description 也沒用,Google 還是會常常自動依網頁內容、使用者搜尋的關鍵字,自動變更 Google SERP 裡的網頁標題與描述!
但是搭配後面其他項目一起看,仍然讓 Google 破功。
網站最重要的、要在搜尋引擎見人的公開內容、能否吸引人的第一印象–Google SERP 上的標題和描述,仍然是大部分頁面都長得一模一樣。
2.產品單頁、產品清單頁的主要內容都用 AJAX 載入
各頁面都有一個獨立不重複的URL,但是主要內文都是用 AJAX 載入,本以為是為了做什麼換頁或載入特效,但實際使用起來,在視覺特效或 UI 順暢度也沒有甚麼特殊設計,不知道前人為何要這樣設計?
這還是很久以前的網頁,那時候 Single Page Application / Server Side Render 都還沒成為潮名詞。
從 Google Search Console 檢查,在多年後的今天是能正確擷取到 ajax 塞進來的頁面內文資料,但當初製作的時空背景,Google 對於這種網頁的檢索應該還是非常弱的。
曾經的台灣第一入口網站 – Yahoo 奇摩的搜尋引擎爬蟲也不知道有沒有這麼聰明就是了。(沒有 Bing webmaster tool 權限,打死不幫忙上傳認證檔案,所以不知道 Yahoo Bing 的索引情況)
3.沒有 RWD,而用了大小網的設計
網站很多年前建置的,但行動版網頁是前幾年後來才加的,要是 Google 的行動內容優先索引計畫 Mobile Index First 政策早幾年公告出來,決策人員當初大概就不會決定做大小網。
現在用電腦版 Google 常常搜到該網站 mobile 版的頁面,搜尋品牌字有出現 sitelink,但點進去也是都連到 mobile 版頁面,在電腦上看這種內容比較精簡,字跟按鈕大大的 mobile 版頁面,就是感覺怪怪的。
最可怕的是 PC 版網站由外包廠商A製作,而 mobile 版的網站由另外一家外包廠商 B 製作,每次要修改功能,就是一場大戰。
4.看似很多頁,但搜尋引擎只有一頁的真 single page url
頁面的內容架構非常複雜,大致有以下幾種:
1.url 後面接一堆不明用途的 get 參數的那種,說是有搜尋排序或特殊功能就算了,但就完全不是。
2.有些頁面又硬是用一些 router 技術,讓網頁路徑硬加上好幾層無意義的目錄名稱。
3.有些頁面又用錨點 (#字號後面接 ID) 來當做每一個分類商品列表頁的網址,
4.特殊活動頁,直接丟一個檔案目錄在主機上,資料夾裡面的程式又有各自的邏輯。
用錨點名稱當做不同頁面,也沒用 Google 從前建議的片段網址 #! 之類的處理方式,所以網站某部分看似有 N 頁不同網址的東西,但是在 Google 搜尋出來就只有一頁…真的 single。
想當然爾,頁面也沒有好好的用 H1, H2 的頁面資料層級,和語意標籤,圖片 img 也沒有補 alt 替代文字,導覽列跟產品資訊的當然也沒有做結構化資料,爬蟲心裡苦,但爬蟲不說。
But,人生最難就是這個 but,這種品牌力和知名度強大,品牌字的搜尋量很高,外部連結不少,還有預算下數位廣告,還有好幾個專業部門負責網站營運,這些低級的 SEO 問題都不是問題。
系統功能先求有,再求好,網站 SEO 相關技術是持續在演進的東西,細水長流才是做生意的道理。
結論
1.從事各產業底層實作人員的可悲之處之一,明明不甘你的事,有問題卻找你。
對外包公司的資方而言,網站問題越多是增加工作機會,但對基層工作人員又是一個在工作排程中插隊的東西,要排查問題,然後層層溝通,沒人要配合。
不過我們還是要心懷感恩,還好網管沒回說 403 error 不關他的事,等出現 5xx 錯誤再來談。
2.網站被「解封」之後,Google Search Console 的檢查網址的「Google 索引」會有很長一段時間還是會顯示「網頁擷取狀態:失敗」,要用右邊有一個「測試線上網址」的按鈕,才能確認網頁已經能正常被檢索與擷取。
3.伺服器的資安管理真是博大精深。
4.Google 的 Mobile Index First 政策看來已經正式實施上線了,像這種有大小網的網站,使用桌上型電腦在 Google 搜尋品牌字,SERP 上的 Sitelinks 上顯示的都是行動版網站的網址。在 Google Search Console 內把電腦版網頁丟進去測,檢索到的頁面內容也都是行動版的內容,難怪這半年國內許多大型網站(如高鐵官網、friDay購物),都在把這種大小網的網站改版成 RWD 的。