
網頁 SEO 奧步? 讓 Google 圖片搜尋把日本搞笑藝人變成東大教授
前陣子大地震時有個趣味新聞,又是 Google 圖片搜尋在鬧事,值得我們這種基層工作人員引以為戒。
事件始末大致是劉寶傑在某天的《關鍵時刻》節目討論地震話題時,引用日本地震學者、東京大學名譽教授笠原順三的一些版塊說法。
結果節目畫面上,笠原順三的配圖放的是日本綜藝節目知名主持人有吉弘行的頭像照片,有在看日綜的網友馬上就看出不對勁,分享到網路上,遂成為笑話一則。
不只一些新聞媒體記者把那個社群貼文發成新聞,連有吉大師自己也在推特發文
「台湾のニュース番組
東大の教授に間違われてるやつ。
まあいいよ。」
我們可以從中學到什麼事呢?
因為網頁前端的程式寫法問題,只要曾經出現在頁面上的圖片,都有機會變成笠原順三教授...
一、Google 搜尋提供高品質、可靠性的資訊?
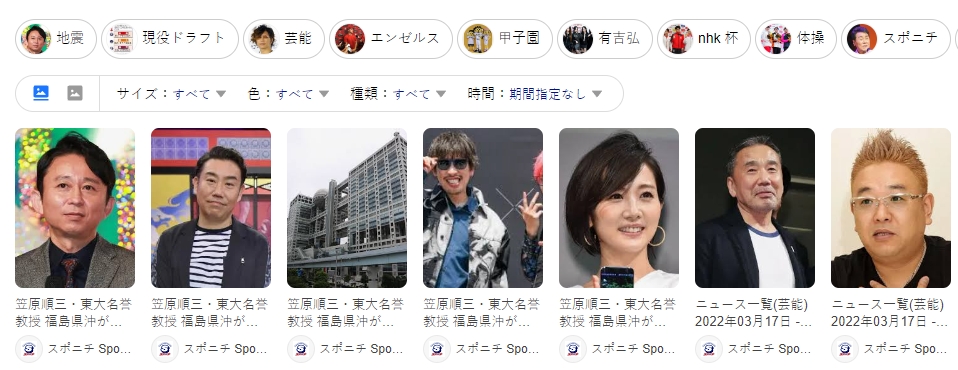
現在去搜尋教授名字,可能會出現一大堆台灣網路新聞對此事件做的封面圖,
在新聞還沒出來前,去 Google 搜尋教授名字,的確會出現有吉弘行的頭像照片(如下圖),還名列前茅:
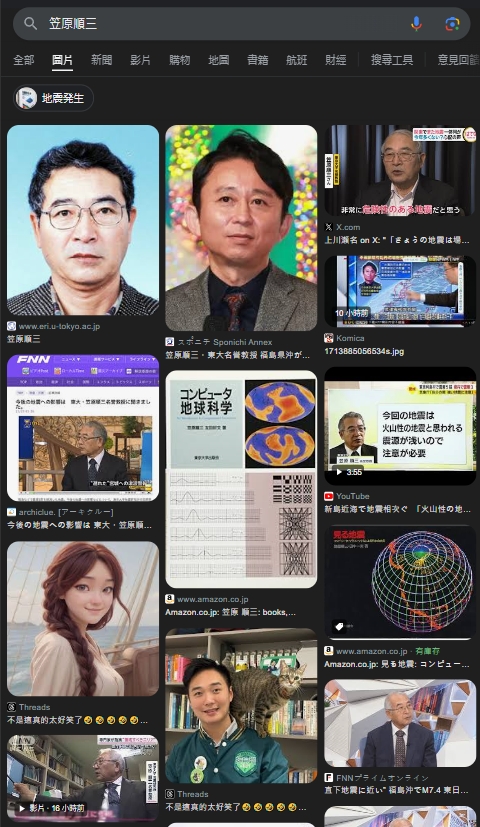
這能算 Google 的問題嗎? 那怎麼沒人說肩膀上站著貓的男生,或是那個 AI 頭像的女生是東大教授? 分明就是工作人員的疏失。
不知道從何時開始,有些人都會以為 Google 上面找到的東西是對的,然後用自己找到的東西去討論(ㄓˊ一ˊ)其他專業人員,例如下面這個影片:
也有些人會要求 Google 搜尋能提供高品質、可靠性的資訊,要是看到內容農場或一些亂七八糟的網頁出現在搜尋結果,就臭罵 Google。
可能是 Google 自己在 Information Quality – How Google Search Works 等各種公開場合也這麼說
Google Search is built from the ground up to deliver reliable, helpful, and high-quality information.
說實在的,搜尋結果跑出來的那堆網頁又不是 Google 做的,為什麼 Google 要當聖人呢?
關鍵字廣告誰出的錢多,誰就排在前面,為什麼 Google 還要弄什麼品質分數跟一堆複雜機制?
自然排序就看誰的程式碼把 meta keyword 塞爆就排前面,Google 幹嘛要幫使用者挑選優質內容,搞得自己這麼辛苦?
尤其是現在一些生成式 AI 的相關功能,Google AI 生成的內容更是被全世界放大檢視,要是有政治不正確、內容回答錯誤,一不小心就要重演谷歌聊天機器人Bard回答問題失誤 母公司Alphabet盤中股價暴跌逾8%的歷史。
鐵鎚釘釘子,釘子釘木板,對於製作網頁的人、經營網站的人,時不時也感覺的得到來自 Google 的壓力,Google 祭出各種政策來打擊那些劣質網頁,一些正常經營的網站,搞不好一不小心就進入系統判定的劣質網頁之列。
不過 Google 是美國公司,犯文字獄的情況至少不會像對岸中國一樣嚴重,像元語智能回答一些政治敏感問題而被下架整改,或是中國還有《互聯網資訊服務深度合成管理規定》,做影像/視訊生成、智慧對話 AI 等應用,要先跟政府登記備案。
二、原來節目用的圖片也只是上網隨便抓的
想像中的要求教授本人授權提供照片,各種嚴謹流程並沒有發生,原來節目要用的圖片也只是上網隨便抓的。
節目的工作人員,也犯了全天下想便宜行事的公司或組織都會犯的錯。
但不曉得這是不是什麼電視台吸引討論的暗黑兵法,要是沒出現這個搞笑新聞,有些很久沒看電視的人,可能還不知道關鍵時刻這種優秀的節目到現在還在播?
當然換個角度想,關鍵時刻的名氣,應該不需要這種奧步。
這裡沒有想討論影視慘業的薪水有多低,畢竟現在民不聊生(?),保時捷 2023 年台灣銷量一枝獨秀暴增19%,竹北還多開了一座展示中心,這些都跟影視慘業基層工作人員沒什麼關係。
三、搜尋教授名字會出現搞笑藝人
依照 Google 目前的搜尋技術說法,搜尋引擎爬蟲檢索網頁時,不會使用 OCR 或是人臉辨識去仔細探討網頁內的每張圖片到底有什麼東西,這樣消耗系統資源,成本太高了。
單純只有建立一些特徵,讓圖片依照顏色搜尋、以圖搜圖時可以找到,還有利用替代文字或頁面上的文字,來跟使用者搜尋的關鍵字作關聯,例如這段網頁顯示圖片的 HTML 原始碼 :<img src="puppy.jpg" alt="黃金獵犬" /> 透過 alt 屬性加註的文字,讓機器知道這張圖是黃金獵犬。
更多內容可參考官方說明:
– Google 圖片搜尋引擎最佳化 (SEO) 的最佳做法
– 加上版權相關的圖片結構化資料
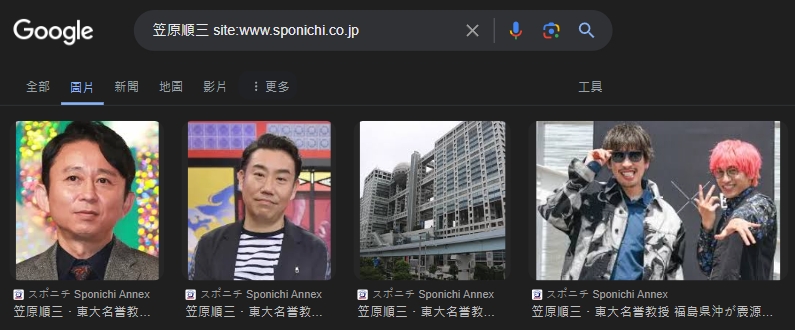
那這個搜尋教授名字,出現搞笑藝人的網頁,HTML 到底排成怎樣?
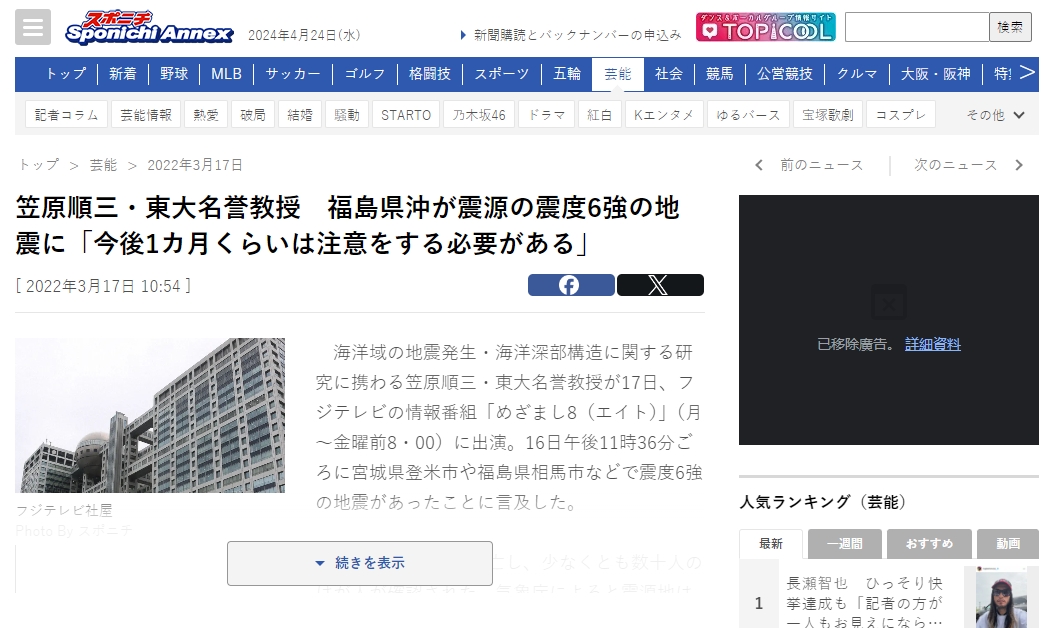
當事網頁在此 笠原順三・東大名誉教授 福島県沖が震源の震度6強の地震に「今後1カ月くらいは注意をする必要がある」
內文雖然講的是教授的地震資訊,只有三大段,內文壓根沒有放上教授的照片,頂多擺了一張台場的那個球形建築知名地標的照片(如下圖):
有吉大師的照片在底下的相關新聞區(如下圖),簡直毫不相干。
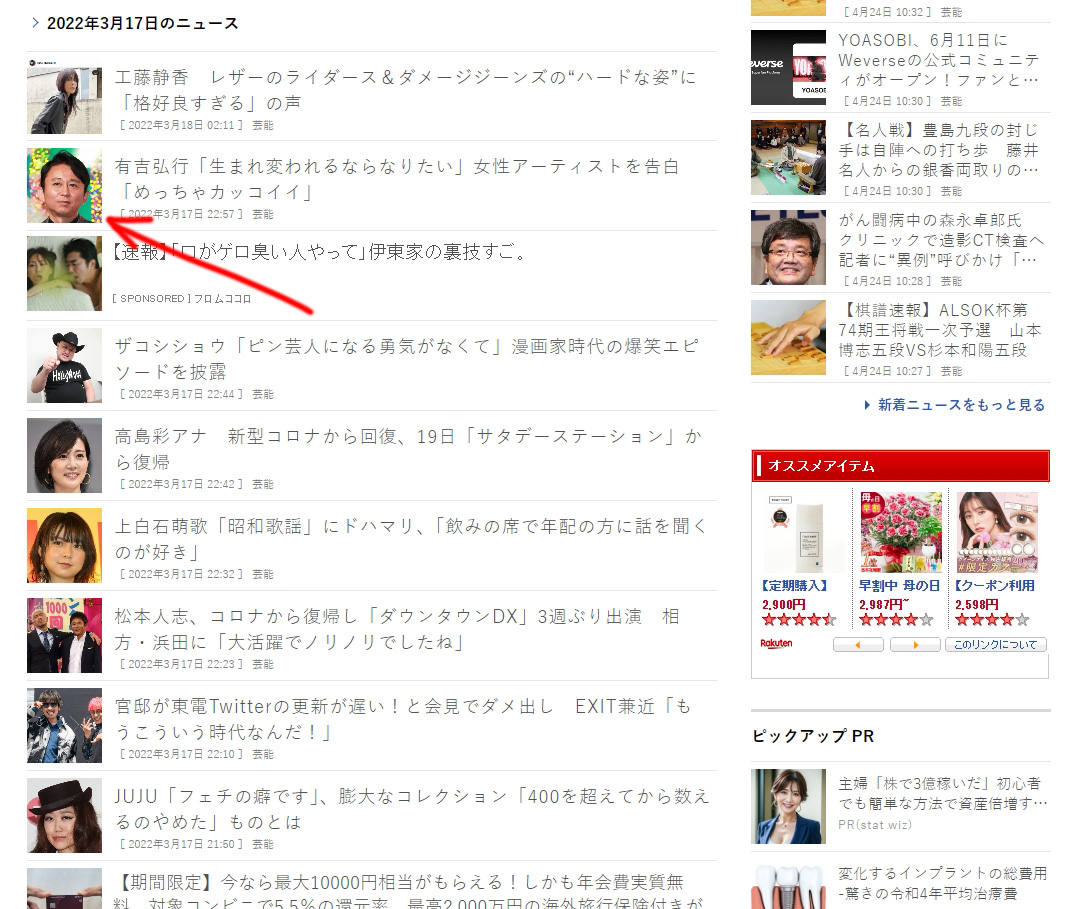
新聞內文跟相關文章清單是兩個不同區塊,這只是人類視覺眼中的感覺而已。
但搜尋引擎爬蟲看的是頁面的 DOM(Document Object Model),
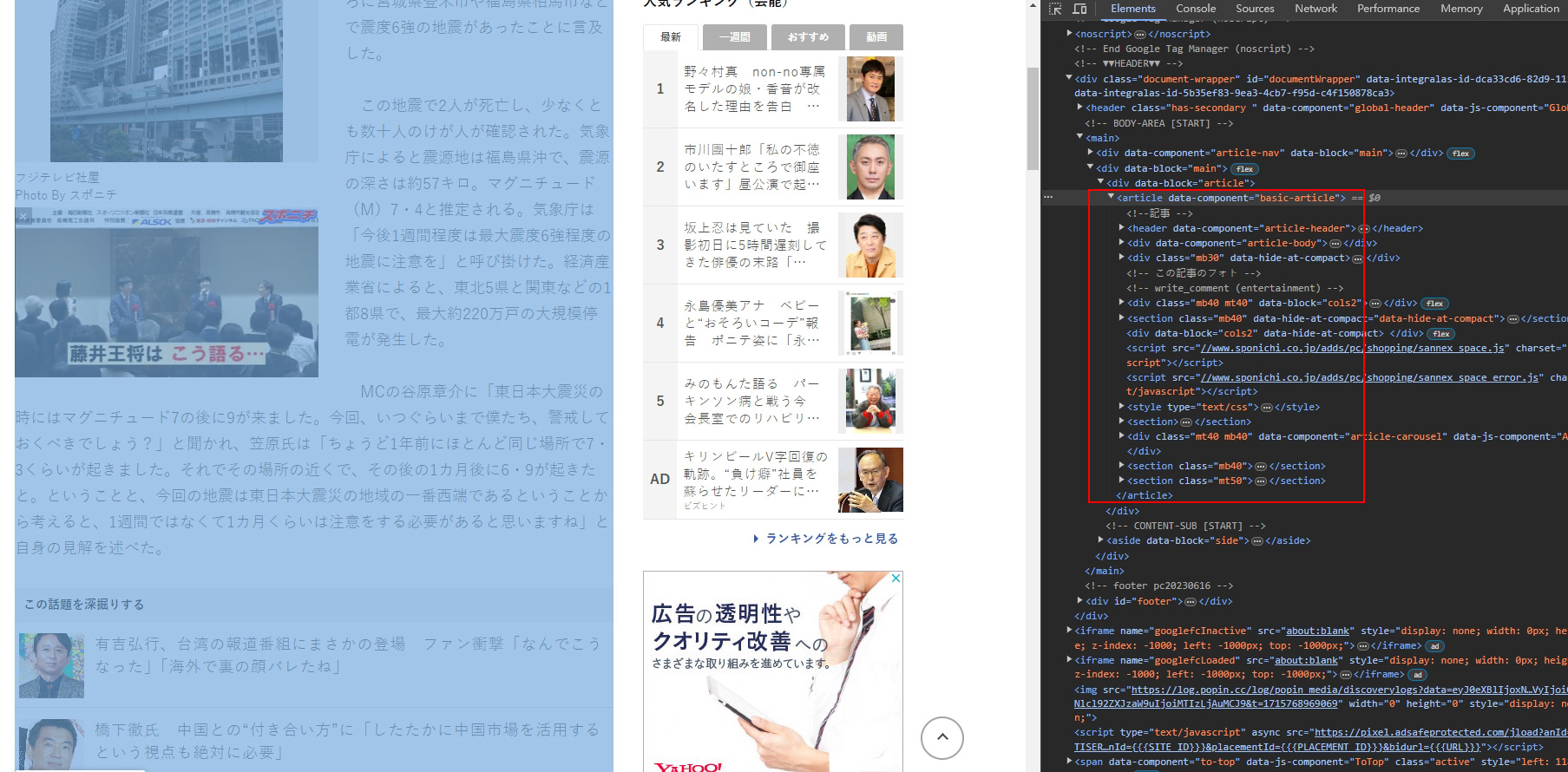
新聞內文區跟相關文章清單都被包在同一個 HTML5 語意標籤 <article> 裡面(如上圖),所以把那些圖片誤認為跟內文相關的話也很正常。
因為相關文章也是會變動的,所以曾經出現在相關文章的封面圖,通通都有機會在搜尋引擎中變成東大教授…
在日本的第二大搜尋引擎 Yahoo! Japan,也可以看到這種奇景
四、不做官網,就失去一個官方的來源
教授自己的網頁(學校給的網頁空間)是打不開的,只有一個東京大學地震研究所的人員介紹頁面上,有一張還算清晰的的小張照片,另外就是一些其他網站的活動照片。
也許教授有 SNS 或其他社群帳號,不是使用漢字?
如果當初教授有個比較像樣的頁面,能讓人輕易找到,也許節目工作人員也不會鬧這笑話了。
結語
搜尋關鍵字時,含有關鍵字的頁面上的圖片,明明毫無相關,卻出現在圖片搜尋結果,這不是什麼新鮮事。但是使用者沒有多加查證就拿來用,可就貽笑大方了。
所以技術上來說,這種問題要怎麼修好它呢? 寫網頁時 HTML5 語意標籤不要亂包就好了。
但這種想法只是從技術出發,真正的技術是為人而服務,對於新聞網站而言,如果這樣可以從搜尋引擎的圖片搜尋中,拐騙到不少流量,讓新聞網站跟廠商談廣告時拿出更好看的數字,為什麼新聞網要把這個問題「修好」呢? 甚至不能說這個是問題呀。
至於這個日本新聞網站這樣的前端程式設計,究竟是有意為之,還是無心插柳柳橙汁,這只有當事新聞網的工程師自己知道了。
希望偶然看到這篇文章的人,可以從這個偶然寫下的廢文中,更加了解網站頁面、網站圖片、搜尋引擎的關係,下次有人問說「為什麼搜尋 XXX 沒有跑出應該要出現的圖片?」知道怎樣是合理的回答,避免讓邪惡的商人見縫插針。