
實測 AI繪圖 Stable Diffusion 是否能真的拯救低畫質圖片和設計師?
前幾天看到一則新聞「AI繪圖」超實用功能?低畫質圖片有救了!網友推爆分享 – Yahoo 新聞,內容節錄如下
不少人應該都有過相同的經驗,那就是好不容易在網路上找到一張圖片,卻因為那張圖片經過多方轉載壓縮,導致畫面解析度大幅下降,嚴重影響觀感。現在有網友發現,可以透過 AI 功能把模糊不清的低畫質圖片調整回高畫質。不僅如此,這項 AI 工具還能夠將文字圖像化,能夠輔助並提供作畫靈感給繪師。
利用 AI 繪圖工具調整設定,便能輕鬆將低畫質圖像重獲新生)
看不到嵌入 FB 貼文的可以點:黃 ヂュオイー
簡單來說報導內容節錄一篇網路上的 FB 貼文,以一張日本動漫風格的人物圖為範例,原圖只有 512x768px 大小,放大一看眼睛部分是模糊充滿像素鋸齒的,畢竟是點陣圖嘛,然後用軟體重新產生一張 2048x3072px 的新圖片,放大來看的話,眼睛部分變成比較清晰平滑的線條。
新聞報導下標有待加強,原始 FB 貼文範例明明就是把小圖重新運算成大圖,解決一些繪師本來畫布沒開這麼大,卻又想把圖拿去輸出的窘境,怎麼就變成低畫質圖片有救了?
圖片小跟低畫質沒有一定的邏輯關係,大圖不一定畫質好,小圖不一定畫質差。
新聞中提到的AI繪圖工具叫做「Stable Diffusion」,最近還有另一套 NovelAI 也很紅,不過因為要錢,而且機器學習的素材來源有爭議,暫時先測試 Stable Diffusion。
本篇主要是測試 Stable Diffusion 的圖片放大術,能否解決設計相關從業者常碰到的工作需求,沒有要討論常見的數位影像或攝影迷思:
- 設備的解析度越高、影像尺寸越大、幾千萬畫素的數字越大、照片檔案佔的磁碟空間數越大,代表成像品質/畫質越好? (不對,還有各種不可忽視的光學或設備問題,例如噪點、光斑鬼影、廣角變形、像素塗抹之類的)
- 設備的解析度越高、影像尺寸越大、幾千萬畫素的數字越大,影像的噪點越少? (例如常有人說這設備有幾千萬畫素,怎麼室內拍攝畫質這麼差? 這還有光圈快門 ISO 值跟很多硬體因素,不是像素越高就好)
- 噪點越少代表畫質越好? (不對,有可能相機用程式算法把噪點塗抹掉了,照片細節變成有點油畫感)
- 不用近看的大圖輸出(例如公車廣告之類的),做稿時文件尺寸要開到 1:1 這麼大? 不用
- 何謂點陣圖與向量圖? (怎麼老是有「JPG 放大會有馬賽克顆粒跑出來」這種奇怪的問題?)
萬一以後有些客人用手機拍螢幕,或是隨便擷一塊圖,然後說請設計師直接用 AI 人工智慧繪圖軟體放大的話怎麼辦?
喔,這不是萬一,應該是我們這行的現在進行式…
讓電腦程式把圖片放大不是新鮮事
如果要讓電腦程式運算,直接把相片中的天空改顏色,人臉加亮磨皮之類的,不用人類自己用一些選取工具選老半天(PS CC 比較新的版本,選取的選單裡面有選擇主體、選擇天空的功能),市面上有不少軟體在做了,連選取都不用特別選,例如巫師後期介紹過的付費軟體 Luminar NEO:
如果是單純靠電腦程式運算把圖片放大,Adobe Photoshop 裡面就有一些補差點/重新取樣技術,也有許多軟體公司開發販售類似用途的工具,像是
– ON1 Resize AI
– Stockphotos – Image Upscaler
– ClipDrop – Image Upscaler
– Blow Up High Quality Image Resizing 這是 PS 的擴充套件
– bigjpg
甚至還有一些不科學的都市傳說,例如用某些雲端硬碟的圖片預覽工具,把圖放大顯示,然後再擷取螢幕…
至於上述這些工具嘛…一些風景圖片可能運氣不錯,放大後效果還勉強可以。
但大部分要說不失真、效果非常不錯? 是在睜眼說瞎話吧? 邊緣銳化到非常不自然,講不出來的不自然感,人臉或一些細節明顯失真。
該給原始檔的就要原始檔,文字該重打的重打,該重拍、該畫、該描的還是要人工處理。
線上體驗圖片增大術
本文講的圖片放大,是希望得到尺寸較大較清晰的圖片,內容還是跟原來那張圖片。另外還有另一種圖片增大術叫 Outpainting,是把一張圖片構圖畫面外的東西腦補出來。另外還有把正方形的圖片改成寬高 16:9 的那種,有些人也叫圖片放大,暫時不在討論範圍。
如果只是想試試文字生成圖片(txt2img),可以用 Stable Diffusion Demo,不過會經常需要線上排隊。
如果要體驗圖片放大術,除了剛剛上面列的那些,也可以試試 Replicate Collections – Super Resolution,不過可能常常會碰到 CUDA out of memory. 的訊息。
另外還有放在 Google Colab 上的 StableDiffusionUI-Voldemort V1.2.ipynb,但因為有 Colab 免費版有使用時間限制,用久一點很容易碰到 Cannot connect to GPU backend due to usage limit….
因為線上版常常要排隊或是碰到資運耗盡,所以直接在本機 Windows 電腦跑看看!
安裝 Stable Diffusion
之前都以為 Stable Diffusion 跟之前介紹過的 Midjourney 一樣,都只是輸入文字然後產生圖片的工具,看了新聞才知道它還有圖片放大功能,目前主要有幾個大功能:
– txt2img : 從文字生成圖片
– img2img : 從圖片和文字生成圖片
– Extras 調整圖片,有圖片放大的 Upscaler、調整圖片清晰度的 GFPGAN 和 codeformer
在此之前常看到一些比較久以前安裝設定 Stable Diffusion 的文章:
– Running Stable Diffusion on your GPU with less than 10GB of VRAM on Windows
– Running Stable Diffusion on Windows with an AMD GPU
安裝步驟極其複雜,看標題一直以為必須要有 10GB VRAM 的 NVIDIA 顯卡才能跑,
但我是 AMD 的顯卡,顯卡的記憶體也只有 2GB,難道要花一萬元左右買張 RTX2060 12GB 或 RTX3060 12GB 回來,才能完整體驗新聞報導裡的那個功能嗎? 實測之後發現門檻也沒這麼高。
因為 Stable Diffusion 是開放原始碼的,所以有各種神人整合的版本,上面看的那種很複雜的安裝設定文章是原始版本,而新聞裡用的那個是別人整合好的 WebUI 版本。
本次範例也使用簡單的 Stable Diffusion WebUI 版本,只要依照神人打包好的程式 The WebUI GitHub Repo, by AUTOMATIC1111 和安裝步驟進行安裝即可,初次執行 webui-user.bat 時會碰到 Torch is not able to use GPU 的錯誤訊息,應該是我用 AMD 顯卡,沒有 CUDA 核心,軟體啟動檢測失敗的關係。
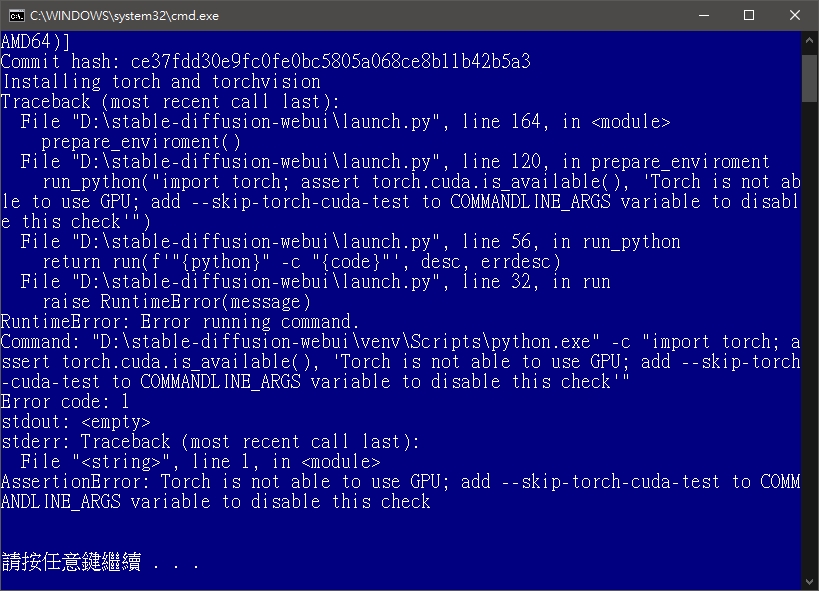
照它提示的訊息,修改 webui-user.bat,把set COMMANDLINE_ARGS=
改成以下這樣,就能正常執行了set COMMANDLINE_ARGS= --lowvram --precision full --no-half --skip-torch-cuda-test
WebUI 版本的 Stable Diffusion 畫面就長這樣
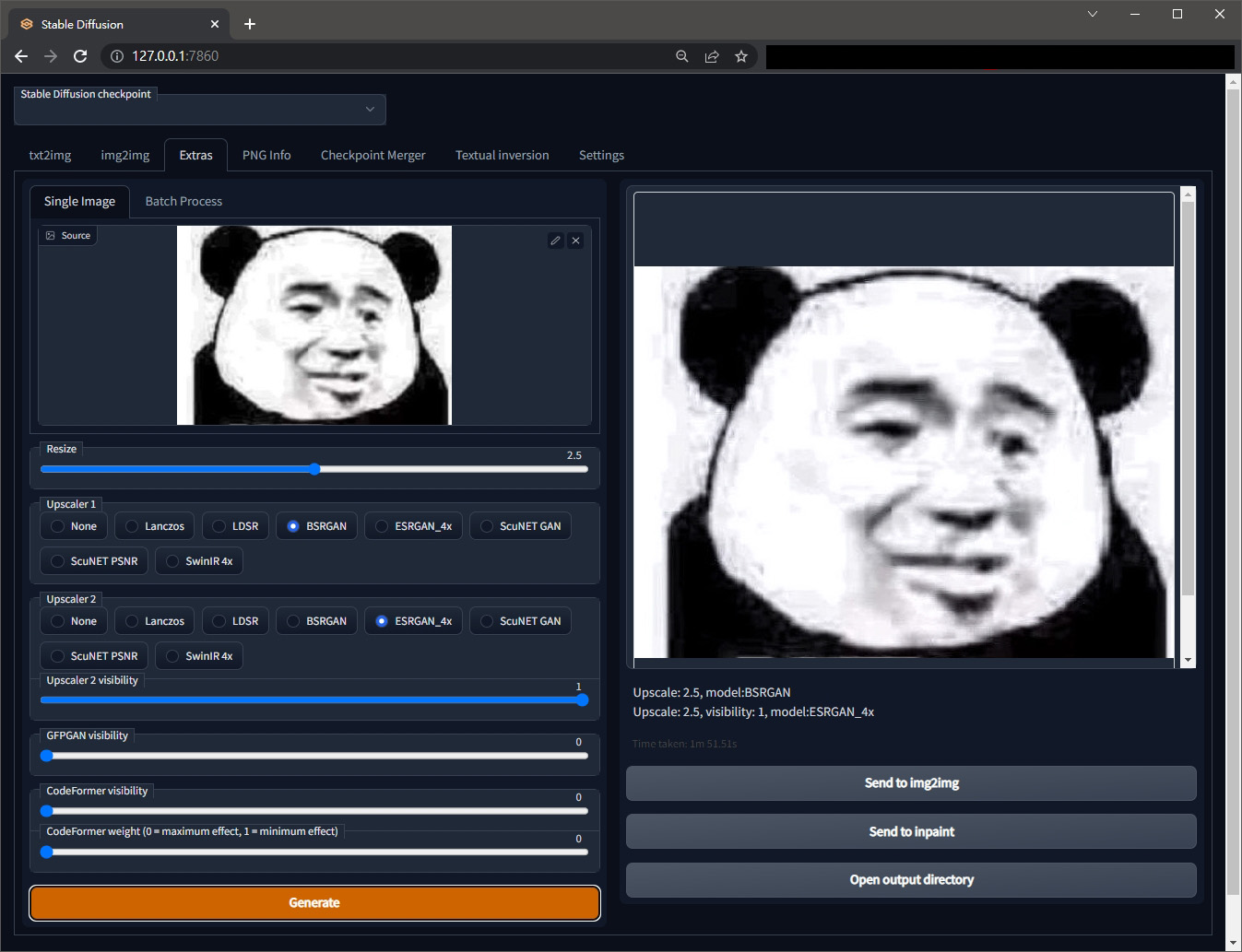
上面的 tab 可以切換不同功能,然後有一堆參數跟選項可以試,圖中左邊是微信熊貓表情包的原始小圖,右邊是運算出來放大後的結果,圖片也會在資料夾的 outputsextras-images 裡面存一份。
這張經典的熊貓表情圖,小小一張圖就有 3 個梗
– 外面的熊貓頭是外國廣告 Never say NO to panda 裡面的熊貓。
– 中間的臉是張學友在電影旺角卡門的表情。
– 外國人應該無法理解為什麼要用畫質這麼差的表情圖,大概只有對岸的人在用,這又牽涉微信的各種機制(如電子包漿),總之是一種網路迷因文化 为什么中国网友最熟悉的表情是一只沙雕熊猫?。
實測 Stable Diffusion 圖片放大功能
上面的可以發現熊貓表情圖片確實變大了,也不像 PS 直接放大跑出一堆像素顆粒,但仍然沒變成高畫質熊貓,用 img2img 再次運算後甚至變成其他可怕的東西。所以繼續測試其他使用情境。
設計行業中,要把小圖片放大的場合其實非常多,例如:
- 做稿、修圖是要給網頁或社群貼文用的,只做小小一張,但是客人說要拿去做成 DM 或其他印刷用途。
- 舊網站是那種像 P 某某商城,一頁塞一大堆小小的商品圖,然而這些比 FB 大頭照尺寸還小的圖,卻要放在商品圖片看得又大又清楚、視覺焦點以商品圖片本身為主的新式網站版型。
- 承上,有人來要商品圖 ai 檔說要做DM,於是把小不拉基的圖片嵌入到 ai 檔交差,肯定是沒法用。
- 圖片超級小,或是找不到原始檔,或是不給向量電子檔,設計師要自己想辦法。
- 業主叫設計師去網頁或是 FB 上面抓照片,但是放在網頁上的圖片為了減少伺服器流量和增加效能,正常情況根本不會放超大的原始檔。
- 原圖是正方形的,然後要重新設計成例如 1920×800 的其他長寬比例,有些人也管這個叫放大?
- 有些設計師給 DEMO 或比稿時會用小圖+浮水印的版本,那要不要擔心客人塗掉浮水印之後直接用 Stable Diffusion 放大修改拿去用? 實際使用之後覺得應該還不擔心這種事。
這幾種情況,重點是需要處理圖片中有文字這回事,我想 AI 不太可能處理好這塊,從官方的範例展示stable diffusion webui feature showcase 也沒有我想看的範例。
自己試了一些圖片,從中挑了幾個,讓不想安裝的人,先參考看看 AI 放大高清圖片的成果。
A.小商品圖放大
原圖取自 Liquor Drink Bottle – Free photo on Pixabay,227x340px
圖庫網有大圖下載,但為了模擬設計現場情況,所以拿小圖來直接放大。

左圖是原始小圖,右邊是放大的運算結果。

傳統放大、AI 放大、有原始大圖可以編輯的情況做對比
用小螢幕的手機,沒有用手指拉大來看可能感覺沒問題,但是用電腦看可是一清二楚,AI 放大之後的圖,背景漸層色階有斷點,瓶子邊緣相當不自然,而且有不少噪點。GFPGAN visibility 參數拉滿的話噪點會變少,但變得有點不像玻璃,而且會拉長運算時間。
如果只是這種程度的話,Photoshop 除了普通的縮放,在濾鏡功能的 Netural filter 裡面還有個「超縮放(Super Zoom)」的 beta 功能,一樣是 AI 猜圖來把圖放大,除了放大之外一樣可以調整雜色、銳利化,但對於這種有文字標籤的細節成果,還是有點不太滿意,仍需要人工處理。
如果做到完美的話,Stable Diffusion 可能還需要具有文字辨識、字體辨識之類的功能。
B.小認證標章圖片放大
圖片取自各國有機食品認證標誌大全,原圖 303x166px

從上到下,第一組是原始小圖,第二第三組是不同的 GFPGAN visibility。
文字無法辨識,圖形仍然很破碎,
左上的那顆應該是單色的,放大之後變成有內光暈了,
圖形周圍的奇怪點點可以靠拉大 GFPGAN visibility 來解決,但是圖形細節會消失。
跟雲朵、草地、大樓之類的景物不同,這種人造圖形很明顯是 AI 的弱項之一。
如果是人類來處理的話,通常是把圖裁切然後丟到 Google以圖搜圖,找到比較清楚的原始檔,再把上面的標章證號改成自己的。Stable Diffusion 如果以後可以自己去網路上找到那顆圖,然後合成進來,才能完美對付這種需求。
C.人臉的圖放大
圖片取自 Exhibition Visitors Gallery – Free photo on Pixabay,把一張滿是人臉, 647x340px 的圖算成大圖看看,結果直接放下面:

前景民眾毛衣的圖案處理得還不錯,但是後面牆上臉的照片不太能用。
用手機或平板可能看不太出來,後面牆上很多照片的人臉都有一些奇怪的紋路。調整參數有時候可以讓奇怪的紋路消失,但會變成像手繪圖,不像照片。
以上的測試範例,也許繼續調整參數,或是使用其他的 model 檔(本次是使用sd-v1-4.ckpt) 可以得到更完美的結果,不過因為運算時間太長了,先宣告放棄。
D.正方形的圖變成其他長寬比例
Stable Diffusion 的 Upscaler 圖片放大功能目前只能選擇把圖片放大成 1.05~4 倍,沒辦法直接放大成指定尺寸。
只能用 img2img 再重新運算出一張類似的,img2img 也可以指定輸出的圖片尺寸,最大到 2048x2048px
用人類來做的話當然是要重新思考如何構圖排版,重新製作一張圖,最好還要有原始檔,比較方便把原圖中的元素搬動位置。
額外加映: inpaint 功能,畫遮罩修改畫面
Midjourney 主要是在訊息輸入框打指令,所以除了到 Arthub.ai 之類的參考別人的指令(但是一樣的指令可能會得到完全不同的圖),也要學習各種參數操作的寫法
Stable Diffusion 除了關鍵字算圖,webui 版是有操作介面跟選項的,所以也多了一些有趣的功能,以 img2img 的 inpaint 功能為例:
例如說一張現有的照片中,想要無中生有放進去一隻狗?
以往人類設計師的作業思維,要嘛依照照片的光線方向拍攝一隻真的狗,再去背後製到圖片裡面。不然就到圖庫素材網站,找看看有沒有角度跟光線方向適合的狗。
那用 Stable Diffusion 的 AI 繪圖,可以直接用筆刷把希望有狗的地方畫個遮罩(圖上黑色那一坨)
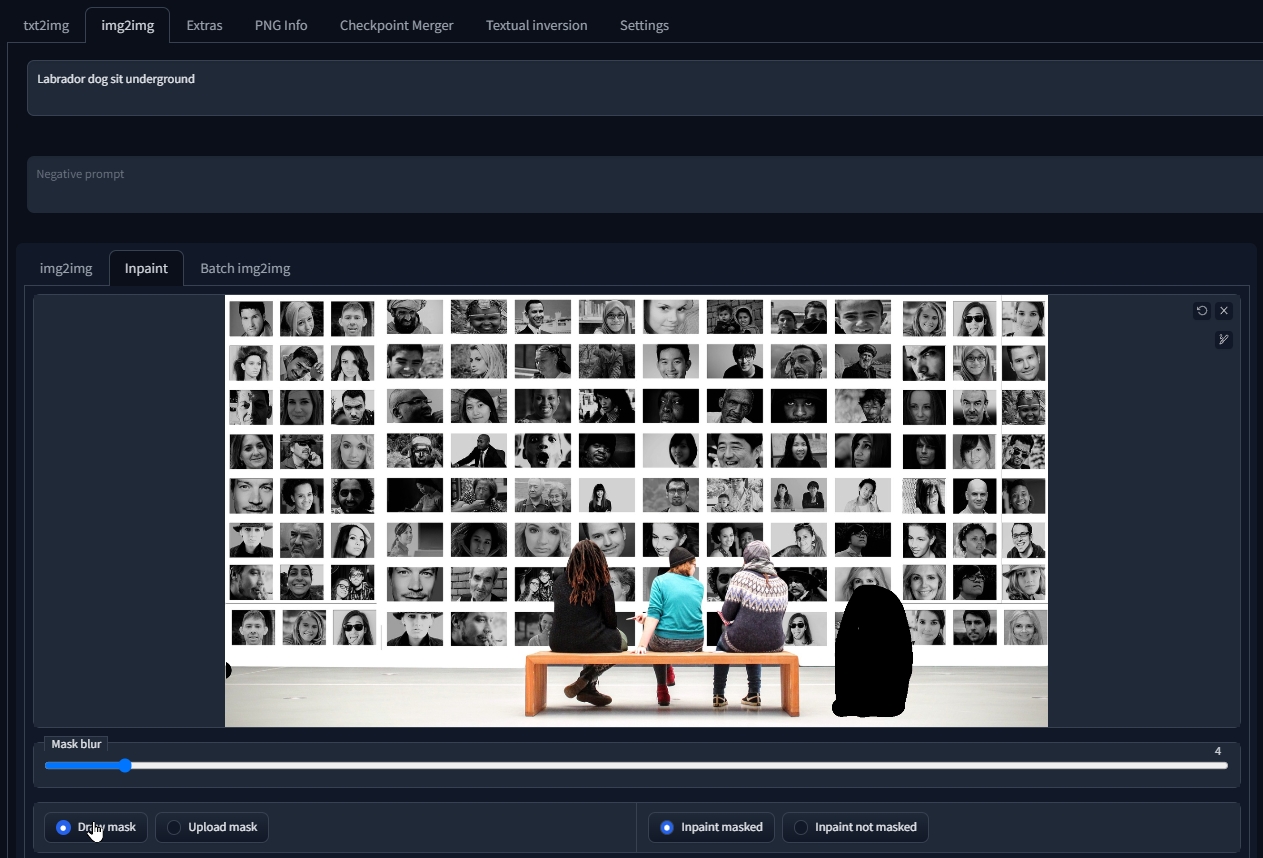
然後調整參數跟關鍵字算了老半天….

還是乖乖買圖庫跟修圖合成吧。
額外加映: outpaint 功能,擴增畫面外內容
Stable Diffusion webui 版本可以在 Img2Img 最底下的 script 找到 outpainting 功能

以剛剛那張博物館照片牆為例,假設需求是左右要延伸出更長的內容,
人類設計師需要把左右的地板和牆壁複製出來,然後複製幾排人像,甚至把人像的順序再打亂,以免被看出來,地板的亮暗部也要調。
那用 AI 繪圖能不能一次成功?
嘗試擴充四邊跟只擴充左右兩邊,挑了二組比較成功的…

真佩服網路上那些成功產生 AI 美圖的人,不知道算了多少張才成功。
Stable Diffusion 現階段 txt2img 也是看不懂中文命令的,中文放進去都會得到一堆像言情小說封面的東西。
效能實測
Stable Diffusion 其實是 AI 和深度學習範疇的東西,在學術研究通常是用專業繪圖卡跟工作站來運算的,或是工程師在自己的電腦上跑,現在因為軟體開放原始碼,還有新聞報導 AI 繪圖有一些特殊引人注目的成果,而走入尋常百姓家。
電腦遊戲討論區老有人在討論 FPS、跑分、顯卡溫度、風扇轉速、電腦螢幕滑鼠鍵盤設備之類的,而 AI 繪圖討論區的紳士都在討論做圖要用什麼關鍵字或技巧,所以電腦跑 Stable Diffusion 很慢的,也不太容易找到說 RTX20 系還是 RTX30 系對於運算速度可以提升多少的測試文章,只能朝「深度學習 顯卡」之類的方向去找。

有一個簡單的判斷方式 : 如果 img2img 時,上圖的命令列視窗顯示 it/s,可以換一張顯卡了。如果已經是 s/it,那再換顯卡可能沒這麼有感。
更新: 知名外國 3C 媒體 Tom’s Hardware 後來也加入了 Stable Diffusion Benchmarked – Which GPU Runs AI Fastest 的評測項目,跑分圖表也會一直更新,基本上就是挑 N 家的卡,
設備1:用 AMD 的顯卡
證明了就算用 AMD 的顯卡,VRAM 只有 2GB,還是可以跑 webui 版的 Stable Diffusion。
- 顯卡: AMD RX550 2GB
- CPU: Intel 4代 i7 (4C8T, 沒超頻)
- RAM: 32GB
實際運算時
– CPU 使用率經常吃滿,CPU 溫度大幅升高,但沒有全時 100% 在跑,有時候進度條跑很久,但是 CPU 使用率也沒有飆高
– 顯卡 GPU 使用率沒有特別高的波動,應該是設備沒有 NVIDIA 的 CUDA,所以工作通通變成 CPU 來做。
– VRAM 跟系統記憶體共用,工作管理員裡面顯示總共有 18GB 可以用,但觀察工作管理員,運算時的 VRAM 使用率跟平常差不多,大概都用掉 4~5GB 而已。
– img2img 算一張 512×512 的圖通常 5 分鐘起跳。
– Upscaler 小圖變大圖也是一張圖數分鐘起跳。
設備2:用 NVIDIA 顯卡
- 顯卡: RTX2060 12GB 雙風扇版
- CPU 與 RAM 與上面相同
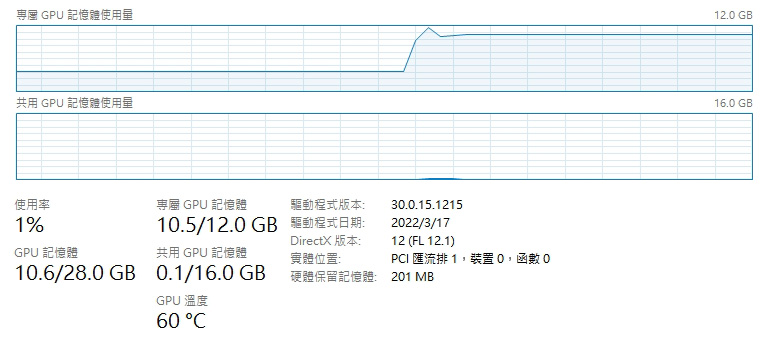
之前設定的啟動參數 set COMMANDLINE_ARGS= 又可以全部清掉了,使用解放的 Stable Diffusion。
實際運算時
– CPU 與 RAM 使用率沒有特別增加
– GPU 溫度快速上升,顯卡風扇變得大聲,會聽到呼呼的風扇聲,溫度將近 70 度
– GPU VRAM 吃得很多(上圖中後段升起來那段)
– img2img 跟 Upscaler 時間大幅縮短至數秒或 1~3 分鐘內
所以電腦配備不夠好的,建議還是不要輕易嘗試,想說用 AI 產生素材,AI 修圖之類的?
可能要經歷一大段花時間、耗電、風扇變得很大聲、怎樣都做不出滿意的圖,做圖效率很低的一段研究期。