
SEO 都市傳說: 網頁超過 15MB 會影響搜尋引擎檢索
之前(之前寫的文章整理後回到這邊PO)有一個 SEO 都市傳說,說網頁超過15MB的,超過的部分爬蟲就不會去爬。所以網頁上放了不管什麼精彩的文案,爬蟲爬不到、別人搜尋不到,就等於沒放一樣。
網頁載入時超過 15MB 很難嗎? 隨便開兩個新聞網的內文頁面,用瀏覽器的 Devtools 看一下。
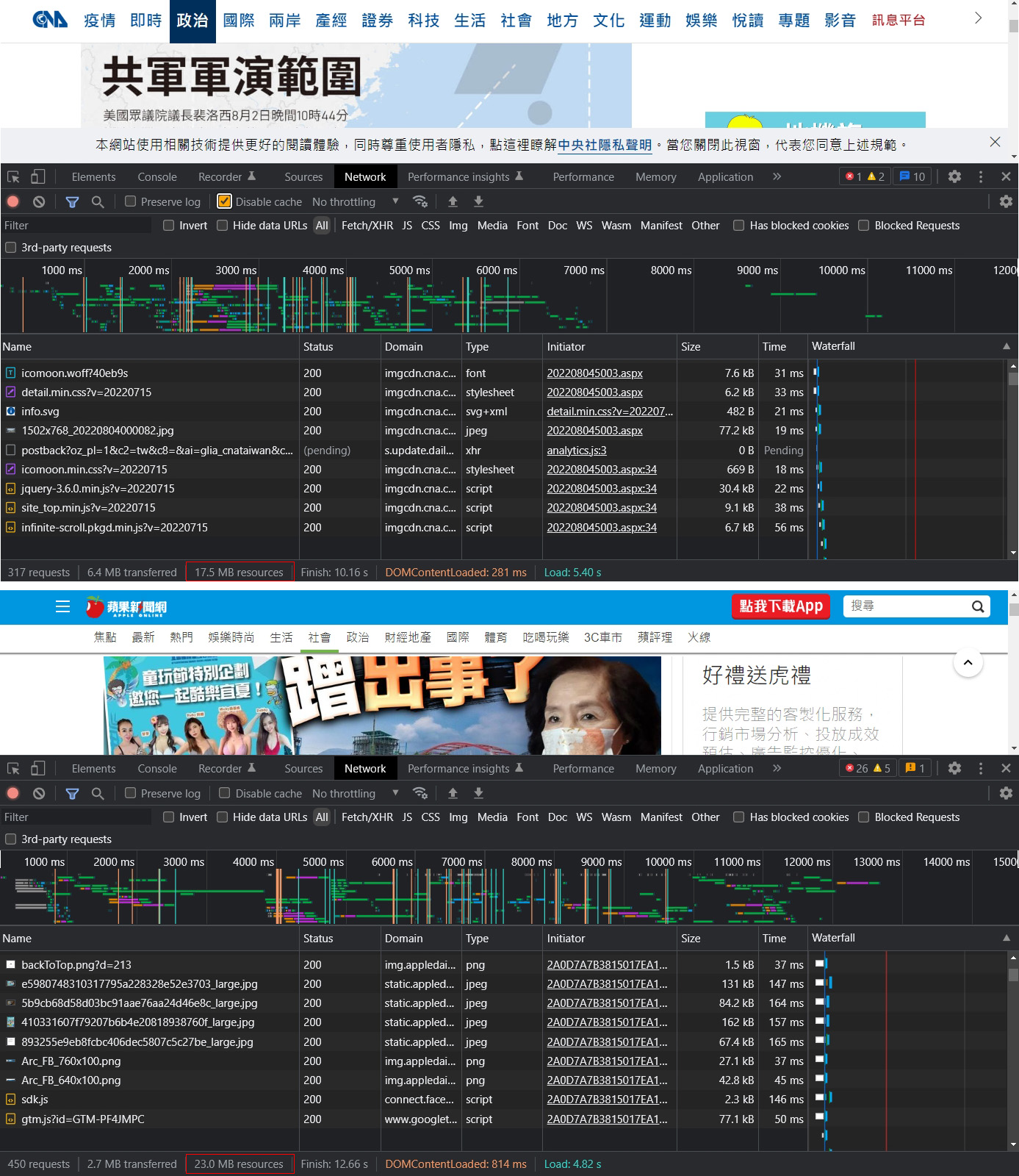
但這樣看其實是不對的,單純看 network 面板最下面那行 resource size 判斷網頁已經超過 15MB?
還有網頁超過 15MB 會影響爬蟲?
來了解這兩件事要如何解讀
在檢索完檔案的前 15 MB 之後,Googlebot 就會停止檢索
15MB 這數字是從哪來的? 應該是從 Google 的官方說明Googlebot 如何存取您的網站,歷史版本怎樣寫我沒有去查,現在當下看到的版本是:
Googlebot 可以檢索 HTML 檔案或支援的文字檔的前 15 MB。HTML 中參照的任何資源 (例如圖片、影片、CSS 和 JavaScript),系統都會分開擷取。在檢索完檔案的前 15 MB 之後,Googlebot 就會停止檢索,而且只會將檔案前 15 MB 納入索引考量。檔案大小限制會套用至未壓縮資料。其他檢索器可能會有不同的限制。
然後有一些可能不是網頁前端專業的,無法理解該段內容,或是望文生義、以訛傳訛,最後就變成整個網頁圖文不可以超過 15MB!
於是在 2022/6 的時候,Google 官方的 Google 搜尋中心網誌又專門發了一篇Googlebot 和 15 MB 的內容
大致就是 15MB 只有算 html 本身,網頁上的 jpg, png 那些圖片是不算的,
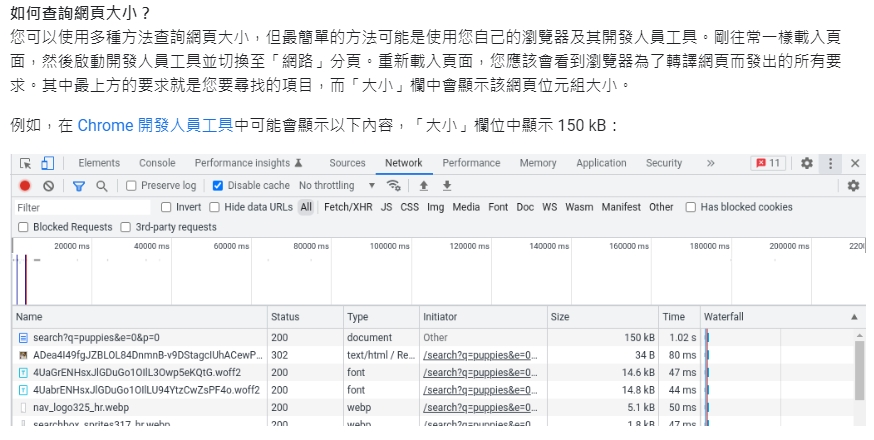
官方說明內也舉了一個非常單純的例子,告訴大家怎麼看網頁有多大。
至於 Devtools 的 Network 面板要如何使用、如何正確解讀數據、Devtools UI 上面的各種「黑話」是什麼,肯定不只是看Chrome DevTools 就能全盤掌握的,就像有人告訴你這是方向盤、這是煞車、這是油門、這是手煞/電子手煞,這樣馬上就會開車甩尾了嗎? 這個肯定不只是工具會不會操作的問題。本文先不探討題目這麼大的問題。
怎樣的網頁 html 會超過 15MB?
在用正確的方法觀測後,開頭那個蘋果新聞網的內文頁只有 20 幾KB,中央社的內文頁只有 30 幾KB,Google bot 檢索應該大致上是沒問題的,至於能不能列入索引,在排名上很容易找到,這又是另外兩回事了。
Apple 的一頁式產品網頁這麼多內容,html 本體也才幾十KB,有哪些網頁可能會發生超過 15MB 的問題?
豐富的頁尾連結?
不少現代網站設計常常會在頁尾放一大堆連結當作網站地圖,但本文不是討論 Web UI 或 UX,也不是討論為了每次頁面產生這一層又一層的連結會讓 SQL 耗費多少資源,效能要怎麼優化之類的問題。只單純探討這東西可能會讓網頁本體增加幾 KB。
隨便找了個頁尾很多連結的網站,整個網頁 html size 也才 33.4KB 而已。

該網頁 footer 整塊有 7000 多個字元,大約是 7828 bytes,依照二進位或十進位算法,大約是 7.6~7.8KB 左右,距離15MB顯然還有很大的空間,非常安心。
直接把 Word/Excel 內容貼到編輯區?
網頁上只有寥寥幾個字,簡單的表格,但其實在原始碼內產生了非常多餘的東西。

內文字數跟多餘的網頁原始碼不一定成正比,但要超過 15MB…那內文應該至少超過上萬字了。
如果是有後台上稿的 CMS 系統,在此之前可能會先撞到一些資料庫欄位長度的限制,例如出現無法儲存,或送出後被截斷的問題。
採用的網頁技術本身?
網頁本身內容很少,但是 html 碼卻非常肥? 也是有可能的,例如以下幾種情況:
- 一些前端 framework 的功能,會為 Modules 動態產生 dynamic class name,或是動態產生 N 層 div 元件,或是會動態產生 css。
- 後端相關的如 ASP.Net 的 ViewState(aspNetHidden) 字串,或是在網頁內自動產生一些有的沒的 token 值。
- 一些懶人架站工具,或 WordPress 的第三方 block editor 套件,很容易在網頁產生異常複雜的 html 和 inline css。
- 使用一些套裝電商或 CMS 系統,某些特殊需求要另外塞一些 CSS 跟 JS 在頁面上,但無法直接像正常網站開發那樣,另外存成一支 .css 或 .js 檔案再嵌入進去,於是那堆直接擺在網頁內的 CSS 跟 JS 也會讓網頁變大。
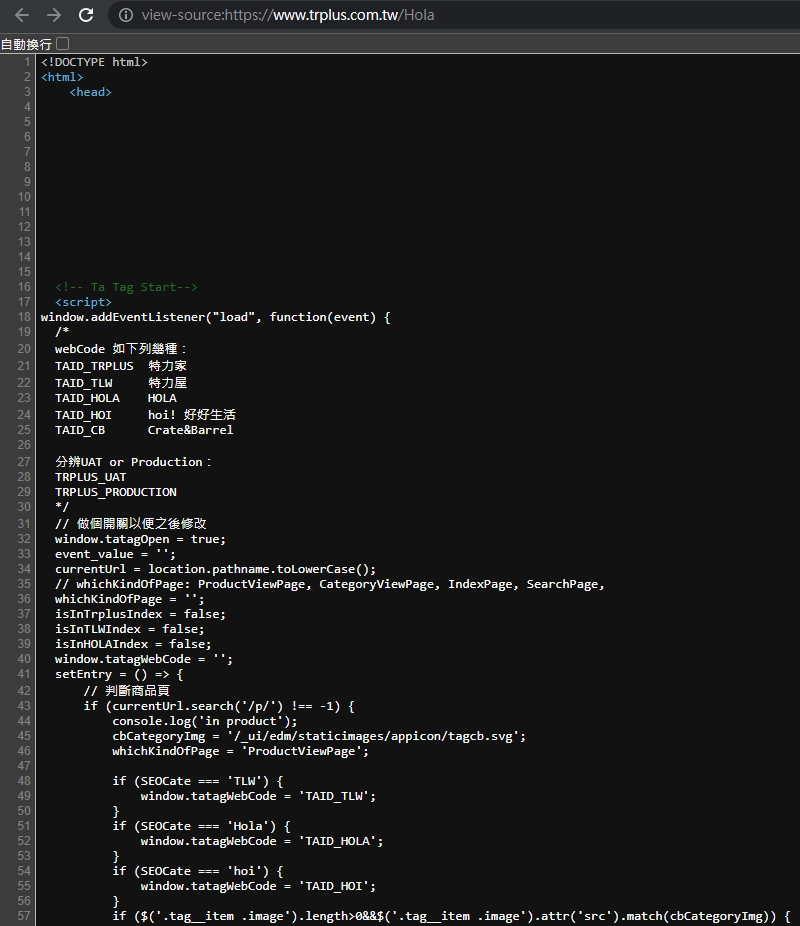
(以最近剛改版的 HXXA 為例)
這些額外產生,又看不到的東西看似讓 html 本體變肥,但算一算通常也頂多幾十或幾百 KB 罷了,在 15MB 這個議題上暫時不擔心。
圖片存在資料庫? 非常危險
網頁程式界名言:算術用浮點,遲早被人扁;圖片存在資料庫,_________。
遇過一種實作技法,把圖片轉成 base64 字串存在資料庫,在網頁直接顯示那一整串字串,似乎是一種減少開發時間、減少 IO 檔案讀取寫入、降低權限控管問題(路徑被人猜到就會檔案外流)的應急作法。
大家都說鬼很恐怖,但實際碰到還真要人命,
雖然「肉眼上」看起來一樣是圖文並茂的正常網頁,網站沒什麼人,資料很小量的時候看起來沒什麼事,
但這種作法不但難以利用瀏覽器的暫存快取機制,
還浪費寶貴的資料庫運算資源,
而且原始圖片如果有 200KB,產生出來的字串長度擺在網頁 html 裡面,通常會比 200KB 還大,這種 base64 字串圖片多放幾張,更容易觸犯 google bot 的 15MB 天條了,
google 的說明裡也確實提到這種 Data URIs 會算在裡面。
資料 URI 會增加 HTML 檔案大小?
會。使用 data URIs 會增加 HTML 檔案大小,因為這些內容是包含在 HTML 檔案中。
Bing/Yahoo 有這種限制嗎?
有,而且限制更嚴格,把網頁丟到 Bing Webmaster tool 檢查,會提示只允許 125 KB,而下面的截取預覽的網頁是被截斷的。
原則上限為 125 KB,以確保編目程式能夠在網頁資源中快取所有內容和連結。這基本上表示如果網頁大小過大,搜尋引擎可能無法獲取所有內容,或者可能無法完全快取。
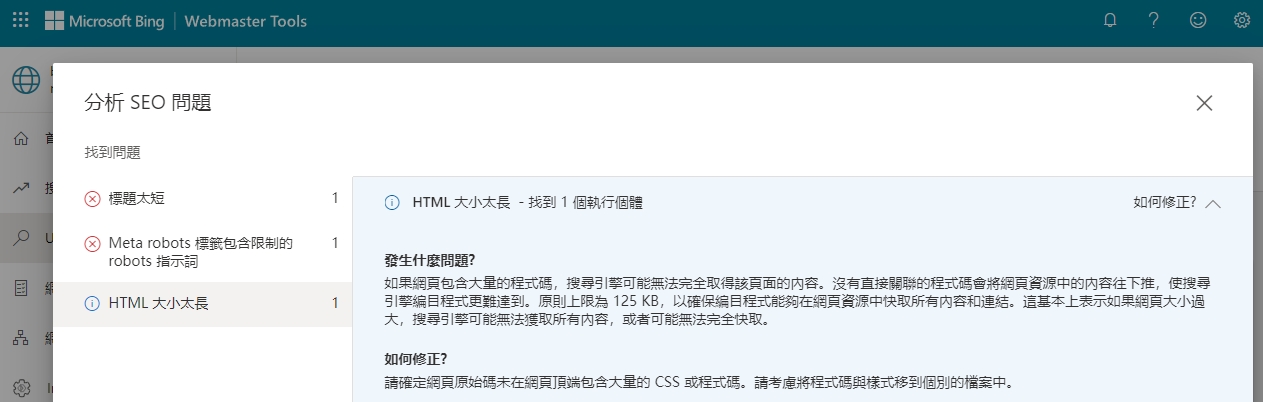
但檢查工具只有把這個列為「注意事項」而不是「錯誤」,檢查工具是否跟實際的爬蟲行為是否一致? 這就需要再花費更多時間測試。