
從 Notion 爬不到的網站得知一個取得頁面資訊的服務 Embed.ly
Notion 有一個功能,貼上網址時可以選擇變成 bookmark 顯示模式,會顯示標題、描述、favicon 之類的,大概長這樣子:

但碰到有一個網站,bookmark 模式跑不出任何資訊,試了首頁跟好幾個內頁網址都一樣,覺得好奇,研究一下它背後的機制是怎做的。
先假設幾種網站不能被 Notion 抓到的問題,再一一求證
1.網站沒設相關的 head 跟 meta og tag?
其實不知道 Notion 會抓哪個,只能自己隨便試一下
網頁如果沒設 head title,也會抓不到,
這個摘要擷取功能跟 LINE、FB、推特的機制都不同,會抓 favicon 而不會抓 og:image,
但看那個有問題的網站都有把相關屬性設好設滿,應該是沒問題。
2.網站用了 SPA 之類的特殊技術,爬蟲無法解讀?
沒有 JS 的情況還是可以看到那些標題資訊,應該是沒問題。
3.站台的資安設定把 bot 程式擋掉?
用 VPN 測試美國 IP 是可以連到網站的,所以應該沒有阻擋海外使用者,那可能網管覺得機器人大量檢索網站太耗資源,結果把那個 bot 或特定 ip 範圍封掉了吧?
依照先前跟「只負責」網管資安的人的經驗,回報的時候最好把 IP, status code、時間點等各種資訊都交上去,不然沒辦法查。不要像有些網路產業的管理者,提交問題只有 3 字真言「有亂碼」「打不開」,還老扯一堆對解決問題毫無幫助的東西。
貼一個測試網址然後自己去看 log

IP 範圍很大,UA 訊息倒是很特別,Embed.ly 是什麼?
一查發現原來是國外的一個服務,從 2010 年創立,主要就是針對各大網站寫好抓頁面摘要資訊的程式,Card 的功能可以把目標網址的資訊嵌在其他網站上,還有針對一些常見的網站例如 FB 貼文、Youtube 影片、TikTok之類的做特殊的嵌入版面設計。
但是會有不太順眼的簡體中文(如下圖),付月費 9 美元可以把右下角 logo 移掉。

另外還有 Emebd.ly API 每個月 99 美金,除了包含剛剛提的 Card 功能,API 功能可以把一串網址內的一些資訊解出來,然後自己另外設計顯示資訊,看起來 Notion 的網址預覽和頁面嵌入功能,是用這個 Embed.ly 的 API 取得使用者貼上的網址的資訊,不是連爬蟲都從頭開始自己寫的。
拿有問題的網址到 Card 的 demo 看一下訊息,403 error,難怪什麼都跑不出來。
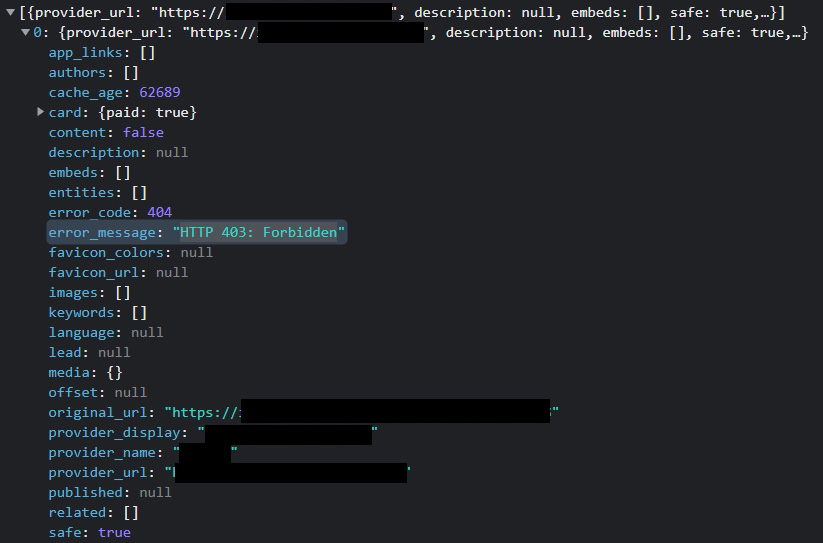
先回報給那個問題網站的人員了。
後續更新
1.隔天問題網站的人員已解決此問題,Notion 的 bookmark 模式可以正常顯示網頁基本資訊。
2.後來又試一下 Notion 的連結 embed 功能,該問題網站在 Notion 的 bookmark 模式正常,但在 embed 模式又無法直接被嵌入&顯示,應該是該問題網站有設定 X-Frame-Options DENY 的檔頭資訊。
但另外試了幾個自己的網頁(非現成的CMS)或是別人的網頁,又都能正常被 embed 模式把內容直接嵌在頁面上,看起來網站應該是不需要特別實作 oEmbed 之類的規格,只要網頁沒有特別擋 X-Frame-Options DENY、是 HTTPS,就可以直接被嵌入。
不過 embed 模式比較少用,無關緊要,就沒有通報了。