
鎖右鍵已經沒人用了,現在大家在防 AI 偷內容
國外的推特帳號發佈了新文章,孔乙己也跟著打開電腦了,所有人都看着他笑,有的叫道:
「孔乙己,你的社群帳號又有新文章可以寫了!」
孔乙己不回答,對 AI 說:
「整理這篇推文串的重點,轉換成繁體中文,改寫成適合 Facebook/Threads 的社群貼文風格,語氣口語一點,加入emoji,並補上延伸觀點與結論,再次確認並優化成更適合社群傳播的版本,最後加上三個吸引點擊的標題。」
AI 很快生成文章,孔乙己看都不看就把文章發出。
旁人又故意朝孔乙己高聲嚷道:
「你一定又拿人家的內容來改寫了!」
孔乙己睜大眼睛說:
「你怎麽這樣憑空汚人清白……」
「什麼清白?我前天親眼見你抓了某家的文章,整篇改寫發出去。」
孔乙己便漲紅了臉,額上的參數條條綻出,爭辯道:
「只是換個說法改寫不能算偷……重組!……AI 的事,能算偷麽?」
接連便是難懂的話,什麼「知識分享」「語意重組」「蒸餾好內容」「我不做也有別人會做」「愛因斯坦的知識也是從其他地方偷的」之類,引得眾人都鬨笑起來;網路內外充滿了快活的空氣。
---
過去網頁設計慘業人員一定都聽過一個需求:「網頁鎖右鍵」,這比較像是心靈安慰,實際上對有心人士,或是自動爬蟲化程式完全沒用。
現在生成式 AI 興起,玩法更多樣,包含但不限於:
- 網站內容被各家 AI 模型大廠搬回去,當成 AI 訓練資料。大家只會覺得大語言模型「知識淵博」,付費給營運 AI 服務的廠商,而不是付費給網站內容的原創者、作者。
- 發佈在網路上的內容輕易被別人盜用,拿去洗稿重製,變成別人的網站文章或社群貼文。
- 自媒體創作者整理一些聯盟行銷分潤的熱門文章,直接讓 AI 改寫語氣,再加一點自己的東西,換上自己的分潤連結,變成自己的文章。
- 把同行網站的 FAQ 或產品資料內容抓回去,品牌名稱取代掉,拿去做 RAG 給 AI 客服聊天機器人用,甚至當成內部知識庫用來訓練新人。
- 把線上課程資料或電子書資料抓下來,整理後變成自己的東西,不只轉售給別人用,還重新變成其他種媒體形式,例如 Podcast、社群圖文、短影片等。
- 在社群網站或影音平台發文,我們在發的不是作品,而是給其他人使用的素材。這些科技巨頭通常自己有 AI 模型,創作者只能無條件接受平台的條款,無償成為 AI 訓練資料。或是產品中有 AI 生成功能,我們的內容可以幫助其他用戶生成二手內容。或是被第三者輕易拿去用。
- 系統中更方便、更自動化的功能,本來需要升級到更高級方案/申請 API KEY才能用的,API KEY還要按用量付費。現在經由一些瀏覽器自動化工具,和輸入自然語言就可以使喚 AI 的用法,可以取代那些本來要付費使用的功能,系統商精心設計的產品方案和會員等級都被打破,賺不到錢。
該如何在自己的網站阻擋這些生成式 AI 的廠商和使用者,我們需要有全新的思維,世界上也有更多的商業解決方案,促進經濟發展,本篇就來探討一下。
AI 用什麼方式來看網站
所謂的「AI 看網站/LLM scraping」其實不只是一種型態,而是至少五種不同的瀏覽方式:
1.像搜尋引擎爬蟲一樣,定時到網路上蒐集資料(AI Crawler)。
最像 Googlebot 的那一類,由 OpenAI、Anthropic、Perplexity 等 AI 大公司運營的常駐爬蟲,會主動循著網路上的連結,定期掃描公開頁面,把頁面內容帶回去另外保存跟處理。
技術上這類爬蟲和傳統搜尋引擎其實差不多:
- 使用固定的 UserAgent 字串值(官方會公告)
- IP range/ASN 可被反查來源(官方會公告/有公開資料)
- 遵循 sitemap、內部連結、甚至 RSS 來擴充抓取範圍
- 多數情況下會遵守 robots.txt
- 內容是在大公司那邊保存一份,而不是每次使用者要查的時候都即時重新抓取
AI 大廠的爬蟲程式將網站資料抓回去之後,這些資料日後將有機會成為 AI 的知識來源或訓練資料。
民眾會覺得 AI 很好用、很聰明,而不是世界上曾經有人辛苦地整理資料給 AI 使用。
2.使用者觸發即時抓取(AI Fetcher)
例如有民眾在 ChatGPT、Claude、OpenClaw 等 AI 工具裡面貼上一個或多個網址,請 AI「幫我總結一下網頁的XX和OO,重新製作成一張圖表」,系統就會透過內部設計的抓取機制,即時抓取該頁內容,然後用 AI 來生成當下那一次的回答。
這時候系統接到需求,背後通常會:
- 呼叫各種 web fetch 工具
- 用特定 UserAgent 字串發送 request(大廠的會有公告出來,例如 ChatGPT-User、Claude-User)
- 即時抓取該頁內容
- 將內容處理後丟給生成式 AI 當 context
在 2025 年 8 月,Cloudflare 就曾經公開發文痛斥 Perplexity 無視那些規則,讓機器人繞過阻擋措施抓走網頁資料。Cloudflare 做了一個實驗,就算在網站設定了 robots.txt 之類的君子協議,Perplexity 還是會把那個網站列為參考來源。完整全文可見: Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives。
Perplexity 那邊的回應則是說他們是幫使用者查資料,不是抓資料回去訓練,難道收 email 的工具或網頁瀏覽器也算一種網路攻擊嗎? 覺得 Cloudflare 是在幫自家的 bot 防護產品炒新聞。回應全文可見: Agents or Bots? Making Sense of AI on the Open Web。
兩邊也是各自陳述各自的事實,阻擋機制被繞過是事實,沒有預存資料、沒有偷拿去訓練可能也是事實。反正這下使用者知道哪家的 AI 比較好用,而不是乖乖守規則,結果一堆網頁都不能查、查不到。
這類請求的特色是:
- 不是長期、定時的爬蟲,不一定會完整保存網站資料。(先不討論 cache 算不算保存資料的問題)
- 為了能更快回應使用者,抓取深度通常只限單一頁面,不太會去爬全站,也不會深度爬取頁面上的其他連結。
- 有些網站的特殊設計(例如需要登入會員/內容完全仰賴 JavaScript render/沒有獨立頁面網址的 SPA 型網站),爬蟲有很大機率會無法正常抓取內容
對網站而言,這類多半還是可以在 log 裡看到特定的爬蟲專用的 user-agent,甚至對應的 IP。
例如把一個網頁連結丟給 Cursor,網站的 access log 會看到:
{一組IP} - - [28/Mar/2026:07:55:52 -0800] "GET /test-test HTTP/1.0" 200 45805 "-" "got (https://github.com/sindresorhus/got)"
{另一組IP} - - [28/Mar/2026:07:55:58 -0800] "GET /test-test HTTP/1.0" 200 1715 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36"
{又另一組IP} - - [28/Mar/2026:07:56:00 -0800] "GET /test-test HTTP/1.0" 200 45805 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36"
真想要阻擋的話,除了那些有明文公佈特徵的,其他都只能靠自己測試研究。
另一方面,有些 AI 工具不一定真的去瀏覽使用者提到的網址,沒有耗費寶貴的系統資源,例如:
- 用其他方式,取得網頁的標題、meta description、搜尋引擎中的摘要,然後開始瞎掰
- 單憑 URL 中的 https://example.com/free-social-marketing-tool 字詞,胡亂瞎掰來生成回答
- 使用過去抓過的快取資料(甚至已經過期),當作即時最新內容來回答
- 網站逾時/執行過久/抓不到內容時,直接用模型的既有知識,瞎掰出一個看起來像答案的東西
這種情況下,網站就不會有真正的爬蟲流量。
在這類情況中,網站根本沒辦法監督網頁內容被生成式 AI 重新統整過的東西長怎樣,
有沒有被 AI 斷章取義?
胡亂改寫成錯誤的東西?
甚至遺失了重要的細節?
3.瀏覽器裡的 AI 助手
例如 ChatGPT Atlas、Microsoft Edge 的側邊欄, Perplexity Comet 的助理這類功能,在之前的AI網頁瀏覽器大戰文章介紹過市面上的幾十種同類產品。
表面上他們都是光鮮亮麗的科技新創、矽谷精英,但實際上都是幫 AI 模型大廠打工......啊,這不是本文討論的內容。
雖然該文章中有一部分關注「用自然語言指揮,讓機器人代替人類自動操作網頁(例如自動填表單、點飲料)」,但那還是持續發展中的功能。別忘了這類 AI 瀏覽器最基本的功能,就是可以讓民眾開著我們的網頁,叫出右鍵選單或側邊欄,讓 AI 利用此網頁資料重新生成一些內容。
對網站程式來說,cookie / session 是有效的,權限等同於使用者本人,AI 程式能讀到的內容,基本就是正常的網頁內容。
就算網站做了什麼限定會員登入瀏覽,一堆阻擋爬蟲流量機制,頁面內容仍然可能已經被帶走,進入 AI 的處理流程裡,傳到雲端做摘要、改寫、重組。
4.各種自動化程式的混合型態
正常的工程師,或會使用 AI 工具的普通人,會透過各種自動化瀏覽器加上 LLM coding agent,寫出可以自己點連結、讀網頁、回答問題的程式,
它們可以做到的事情包括:
- 自己點進分頁、展開 accordion、觸發 lazy load
- 登入網站、使用瀏覽器已登入的工作階段
- 讀取多頁資料後整理成答案
- 模擬人類操作流程完成任務
背後常見技術工具組合通常是:
- Playwright/Puppeteer/各種瀏覽器自動化工具(負責開網頁、點擊、滾動)
- 針對特定防禦產品的繞過策略(例如針對 Cloudflare Turnstile、reCAPTCHA 等反爬蟲機制的繞過方法)
- 針對特定網站的內容解析器(負責解析網頁內容、提取資料)
- LLM(負責理解頁面內容、決定下一步的動作、產生自動化瀏覽器的控制碼)
- 一些設計好的工作流 workflow(例如點進特定頁面、把金額、日期等內容整理成表格、整理成指定格式,存到特定位置)
從網站角度來看,這種流量會變得很棘手:
- 行為接近真人(有滑動、有點擊、有停留時間,各種檔頭資訊瀏覽器功能都可能偽造出來)
- 不一定有固定 user-agent
- 甚至會混用代理服務,網站大費周章限制訪客國家、訪客語言、IP、裝置類型,結果都可能被完全繞過。
單純靠 robots.txt 或封鎖 bot 名稱,通常是擋不住這一類型的,只要網站內容有價值,大家會拚了命、毫無底線的研發各種工具,例如抓推特文章、小紅書等各大社群網站內容的工具,總是一再推陳出新。
尤其現在多模態 AI 大爆發,網頁的 DOM 做了防爬,做一堆替換文字之類的? 那用截圖的,後面自動辨識文字,請問閣下該如何應對?
5.使用 MCP/skill 工具
在前述的方法中,使用者用這些方式讓 AI 幫他們「看網頁」:
- 需要訂閱 ChatGPT、Perplexity,使用這些廠商設計好的流程、消耗廠商的雲端系統資源,如果用量越大,訂閱的月費就越高。
- 要自己寫一堆一些爬蟲程式,有些甚至還是一次性的、專門針對某個網站的。然後整天寫程式、調整程式就飽了。
但在生成式 AI 生態下,還有更本地化、更低成本的玩法:
使用者直接在自己的電腦上,搭配像 Codex、Claude Code 這類工具,再串接以前介紹過的 Chrome MCP 或類似的 browser control 工具,讓 AI 直接操作電腦本機已經登入會員帳號的瀏覽器,來讀取網站內容。
也可以搭配設計好的 skill,例如自動解析網站 DOM 結構、擷取文案語氣與資訊架構,拆解成 UI 元件,並同步生成對應的程式碼。某些情境下,甚至只是看完競品 landing page,或是開個試用帳號把系統功能流程走一遍,就可以直接生成一個版面相似、功能相近的產品網站。
從網站防護的角度來看,這種方式幾乎是目前最難處理的一類:
- 所有請求都來自真實瀏覽器,沒有可辨識的 bot user-agent,僅能依靠 playwright 等工具的特徵來辨識,工具何其多,要偵測到什麼時候?
- 可以模擬人類操作(點擊、輸入、滾動),行為特徵接近真人,但可能機器看的頁數特別快特別多。
- IP 就是一般使用者的家用 IP,甚至是公司之類的網路環境,非常「乾淨」,不是各大機房的 IP,也不是各種有代理痕跡或黑名單的 IP。
- 會執行完整 JavaScript,有登入狀態,拿到的是最終渲染結果。
也就是說,對網站來說,這幾乎也是一個使用者正在正常瀏覽的情境。
在條件允許下,成本降到只要貼一個網址給 AI,網站本身就開始從產品變成素材來源。
AI 改變的不只是流量,而是網站的價值結構
這五種方式的差異,決定了後面防禦策略的難度與成本。
服務的護城河又來到客服、支援、專屬功能等差異化服務,這些都不是單靠複製頁面、文案、功能就能補齊的。當產品本身越容易被重新複製,真正的勝負就看誰能提供更好的整合服務和資源。
例如理論上大家都可以做出 SHOPLINE 電商系統平台,但是 SHOPLINE 有自己的金流 SHOPLINE PAYMENT,還跟其他金流、物流、電子發票、簡訊、行銷工具等各種協力廠商簽約,店家透過 SHOPLINE 一次買齊設定好,比直接對那些第三方廠商的成本還低。
對網站而言,上述情況的網站訪客都是機器人,操作網頁的也是機器人,
那些什麼用心調整的 UI/UX 設計?
精心製作的封面圖?
靠曝光和點擊率跟廠商談判的廣告版位?
成本很高的自動推薦內容、設計一堆演算法?
銷售轉換漏斗設計?
......通通都是在做白工。
然後網站還得扛下機器人流量帶來的伺服器負載、頻寬成本。
接下來的段落,就會針對這幾種不同存取模式,分別討論有哪些現代科技,來減少對網站內容的侵入與重製。
從 robots.txt 開始,先擋掉會守規矩的爬蟲
現在主流 AI 公司多半都有公開自己的爬蟲 user‑agent,並宣稱會乖乖依照網站的 robots.txt 決定能不能抓取該網站的內容。
我們在網站 robots.txt 加入類似這種的內容,來封鎖這些 AI 公司的爬蟲。
User-agent: ClaudeBot
Disallow: /
透過這些設定,做到「只擋訓練、不擋引用」或「全部 AI 都不要來」等不同策略。
像是 OpenAI 的三兄弟
OAI-SearchBot: 用於搜尋功能ChatGPT-User: bot 即時檢索網頁,回答使用者的問題GPTBot: 用於抓網站資料回去訓練模型
來源:Overview of OpenAI Crawlers
Anthropic 的三兄弟
ClaudeBot: 收集訓練資料Claude-User: 當個人向 Claude 提出問題時,可能會存取網站。Claude-SearchBot: 專門分析線上內容以增強搜尋回應的相關性和準確性
來源:Anthropic 是否從網路爬取資料,網站所有者如何阻止爬蟲?
Perplexity 有兩個
PerplexityBot阻擋 Perplexity 把網站當成搜尋結果Perplexity‑User當使用者向 Perplexity 提問時,它可能會訪問網頁以幫助提供準確的答案
Google 在 2023 年弄了一個 Google-Extended
Google-Extended is a standalone product token that web publishers can use to manage whether content Google crawls from their sites may be used for training future generations of Gemini models that power Gemini Apps and Vertex AI API for Gemini and for grounding (providing content from the Google Search index to the model at prompt time to improve factuality and relevancy) in Gemini Apps and Grounding with Google Search on Vertex AI.
(Google-Extended 是獨立產品符記,網站發布商可利用這個符記,控管 Google 從他們網站檢索到的內容是否能用於訓練未來世代的 Gemini 模型,這些模型可為 Gemini 系列應用程式和 Gemini 專用 Vertex AI API 提供技術,並為 Gemini 系列應用程式與 和 Vertex AI 上的 Google 搜尋提供基礎 (在提示時從 Google 搜尋索引提供內容給模型,以提高事實性和相關性)。)
Google-Extended does not impact a site's inclusion in Google Search nor is it used as a ranking signal in Google Search.(Google-Extended 不會影響網站在 Google 搜尋中的收錄情形,也不會當成 Google 搜尋的排名信號。)
來源:
另外還有一些專門做線上資料集的團隊,平常他們的爬蟲會努力抓取網頁資料來建立公開儲存庫。
有些做開源模型的研究者或模型團隊,會使用這些資料集團隊釋出的公開網頁抓取資料集,之後再做清洗,變成可訓練 LLM 的語料。
比較有名的一家是CCBot,主要是由非營利組織 Common Crawl 開發的網路爬蟲,他們官網有自己公佈說要如何封鎖他們,並遵守規則 robots.txt 的規則。
全世界還有非常多家,如果不想一家一家去查,也可以參考一些大型媒體網站的 robots.txt,尤其是那種看文章要付費訂閱的網站,他們通常會比較嚴格地封鎖 AI 爬蟲。
https://www.nytimes.com/robots.txt
https://nypost.com/robots.txt
https://www.economist.com/robots.txt
https://www.theguardian.com/robots.txt
這招的缺點顯而易見:
1.只有遵守 robots.txt 的 AI 才會聽
這方法一點強制力都沒有,爬蟲程式不理 robots.txt,網站也不能怎樣。
這種君子協議有多可笑? 現在打開 Claude Code,丟出一個 URL,要求寫一個爬蟲程式去爬取內容。只會看到 AI 直接用 fetch, file_get_contents. Http::get(), curl, HttpClient 等各種語言適合的方式,直接呼叫該 URL,然後取得內容,打完收工。
我們不會看到 AI 先拆解 URL 中的 hostname,然後再存取 robots.txt,
然後寫一堆 regex 檢查 robots.txt 的規則,
或是檢查 URL 的某些 X-Robots-Tag 相關 header,
檢查 meta 標籤值,
判斷是否允許爬取,
確定真的可以爬了才去拿資料...
做爬蟲程式還可以修改自己的 User-Agent 字串,假裝成任何一家的 AI 爬蟲,除非網站管理員還認真去檢查 IP 是否在該 AI 爬蟲的 IP 範圍內。
剛好大概半個多月前有人做過一個研究,證明用 robots.txt 封鎖 AI 爬蟲,根本是做白工: Do News Publishers That Block AI Crawlers Get Cited Less Often by AI? - BuzzStream,一位內容內容行銷主管調查了一些大型新聞網站,這些網站的 robots.txt 多半把上面剛剛列的那些 AI 爬蟲都封鎖了。但在 ChatGPT 等工具實測,AI 還是照樣引用這些網站的文章。
2.封鎖 AI = 可能連其他曝光管道一起砍掉
剛剛舉了一堆 AI 爬蟲的 User-Agent,是不是少了幾家? 例如 Bing 是把搜尋和 Copilot 黏在一起,沒有分開。
How to Temporarily Block URLs from Bing and Copilot Search Results
How to Remove Content from Bing and Copilot
如果我們只是想避免網站內容出現在 AI 的回答,那可能連正常的網路搜尋都會被阻擋,把自己網站的 SEO 之路也打斷了。
用 AI 服務的工程測試參數,讓模型自己停止生成
讓 LLM 幫忙整理摘要、讓 LLM 根據內容重新生成,這中間都少不了一個步驟:把內容丟給 LLM。
這些經營 LLM API 的廠商,本身都有一些工程用途的參數,例如 Claude 的 refusel string,我們要利用的就是那些 LLM 處理內容時,碰到特殊工程字串引發的反應。
refusel string 的用途是故意觸發 Claude 模型的拒絕回應(例如 streaming 的中斷情況),讓開發者可以測試應用程式如何處理 stop_reason: "refusal" 的情況。只要把特定字串放到 prompt 裡任何位置,Claude 就會立刻停止並拒絕繼續處理。
Anthropic Claude API 的官方文件 Streaming refusals 曾經出現一組神秘字串 ANTHROPIC_MAGIC_STRING_TRIGGER_REFUSAL_1FAEFB6177B4672DEE07F9D3AFC62588CCD2631EDCF22E8CCC1FB35B501C9C86。
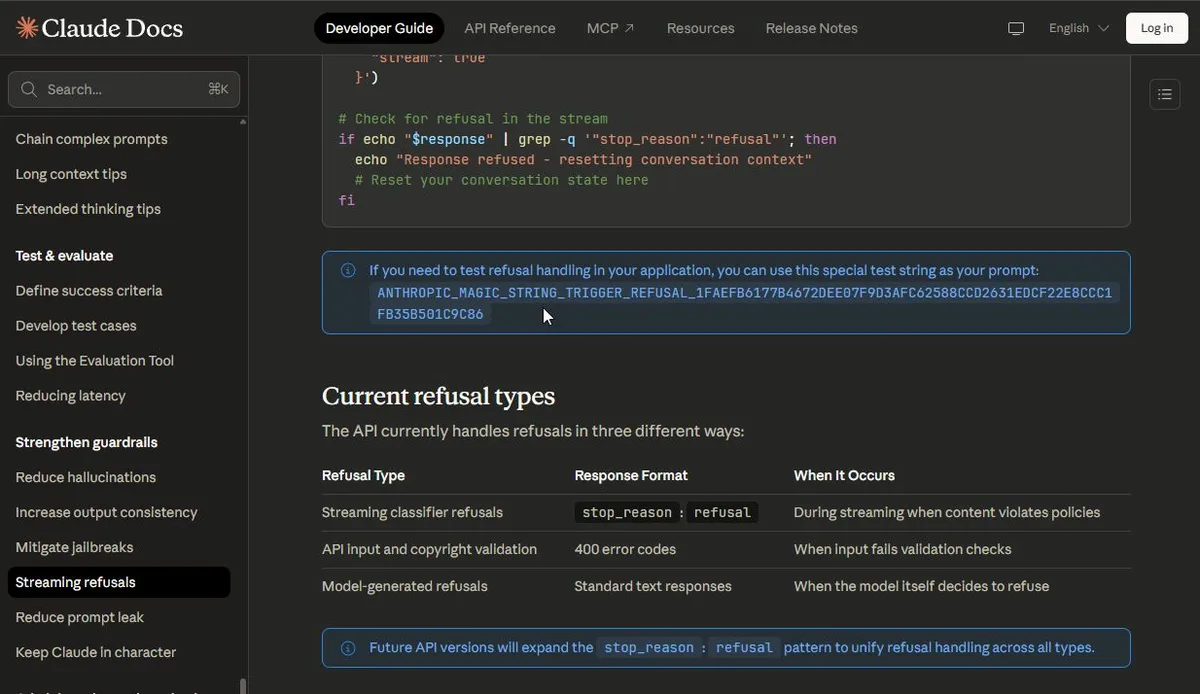
當然還有其他的 ANTHROPIC_MAGIC_STRING,例如在 Amazon Bedrock User Guide 的 Thinking encryption 有提到另一組,用來讓人檢查模型 thinking 時是否運作正常。
這些測試字串還有其他用途,例如會被拿去測試 Claude 的 API 中轉站,會不會廠商明明說是賣 Claude 的模型,卻用其他便宜的模型來頂替?
如果在本文的用途,我們也可以在網站內文加入這些字串,讓 AI 在爬取到內文時觸發拒絕回應,讓 LLM 卡住,從而避免內容被直接使用。
撰文時,Claude 官方文件中的那串字已經不見了。直接拿去試好像也沒啥用。Claude 只會提示說可能存在 Prompt Injection 行為。
而且這種方法只適用於 Claude,世界上還有這麼多 LLM ...。
然後還記得本段第一句話嗎? 其實「把內容丟給 LLM」這句話不一定成立,因為有些系統的處理機制,是先把原始內容分片跟壓縮後再丟給 LLM,或是各種其他的處理機制。
我們在內文中加料動手腳根本沒用,原始資料到了 LLM 那一個處理階段,早就已經是「斷簡殘篇」了。
在網頁開發上導入 WebMCP,但是亂設
現在 AI 還會幫人類去操作網頁,那 AI 能知道底下這個按鈕跟輸入框是什麼功能嗎?
<button type='button'><img src='data:image/png;base64,iVBO....gg=='></button>
<input type='text' name='name1' class='w-full aria-disabled:cursor-not-allowed outline-none focus:outline-none text-stone-800 dark:text-white placeholder:text-stone-600/60 ring-transparent border border-stone-200 transition-all ease-in disabled:opacity-50 disabled:pointer-events-none select-none text-sm py-2 px-2.5 ring shadow-sm bg-white rounded-lg duration-100 hover:border-stone-300 hover:ring-none focus:border-stone-400 focus:ring-none peer'>
網頁的按鈕上沒有什麼無障礙的 aria 屬性,輸入框也沒有什麼 label 或 placeholder,按鈕文字還是一張圖片,AI 在執行任務時根本是在瞎猜。
當然有些人會說 AI 是不會錯的,都是負責操作 AI 的那個人不會用?
拉回主題,本段的主角 WebMCP 由 Google 與 Microsoft 共同提出,在上個月(2026年2月)推出預覽版本 WebMCP is available for early preview。
WebMCP 這類新興協定,就是專門讓網站定義 AI agents 要怎麼跟網站互動,網站可以用標準化的描述,把功能寫給 LLM 看,讓 AI 不需要亂抓 DOM,而是走網站設計好的通道。
在一些 2025 年夏天的早期的範例程式碼 Declarative API for WebMCP、webmachinelearning/webmcp 中,可以看到網頁中的表單物件多了一堆 tool 什麼的屬性,類似這樣的寫法:
<form
toolname="尋找班機"
tooldescription="搜尋兩個機場之間特定日期的可用航班"
toolautosubmit
>
<input
name="origin"
type="text"
required
pattern="[A-Z]{3}"
placeholder="e.g., SFO"
toolparamdescription="三字母IATA起飛機場代碼,例如 SFO"
>
</form>
網頁工程師看到這程式碼又要開始吐槽了,誰還在用這種古老的 html element 寫表單元件? 表單也不一定要寫個 form 了,團隊用的元件庫建置時會過濾未定義的屬性,LLM 發請求時要怎麼處理 CSRF 啊? 還有欄位之間有相依的驗證邏輯怎麼弄?
上面這種在 HTML 裡塞一堆 tool 什麼屬性的,叫 Declarative API (宣告式 API),WebMCP 還有另一種 Imperative API(指令式 API)。
不需要改 HTML 表單,而是直接在 JavaScript 裡增加程式碼 navigator.modelContext.registerTool(),把現有的 JS function 包裝成 AI agent 可以呼叫的 tool。範例大概長這樣:
if ('modelContext' in navigator) {
navigator.modelContext.registerTool({
name: "尋找班機", // 工具名稱
description: "搜尋兩個機場之間特定日期的可用航班",
title: "航班搜尋工具", // 可選,人類可讀標題
inputSchema: { // JSON Schema,定義參數
type: "object",
properties: {
origin: {
type: "string",
pattern: "^[A-Z]{3}$",
description: "三字母 IATA 起飛機場代碼,例如 SFO"
},
destination: { /* 同上 */ },
date: {
type: "string",
format: "date",
description: "出發日期 YYYY-MM-DD"
}
},
required: ["origin", "destination", "date"]
},
execute: async (input, client) => {
// 這裡放你原本的業務邏輯(fetch API、Redux action、CSRF token 處理…)
console.log("AI 呼叫了工具,參數是", input);
// 可以要求使用者確認(human-in-the-loop)
const confirmed = await client.requestUserInteraction(async () => {
return confirm(`AI 想用以下參數搜尋航班:${JSON.stringify(input)}`);
});
if (!confirmed) throw new Error("使用者拒絕");
// 真正執行
const res = await fetch('/api/flights', {
method: 'POST',
body: JSON.stringify(input),
headers: { 'X-CSRF-Token': getCsrfToken() }
});
return await res.json();
},
annotations: {
readOnlyHint: false, // 會修改狀態就設 false
untrustedContentHint: false
}
});
}
這種寫法對現代網頁開發可能更友善:
- 不用到處硬塞 tool*** 屬性,然後擔心在建置時會被過濾掉。
- 可以直接重用現有 JS 函式片段,不用重寫成 form。
- 能處理更複雜的狀態(登入、購物車、即時驗證、CSRF、相依欄位…)。
- 支援
unregisterTool()、provideContext()等方法,頁面狀態改變時,可以動態更新工具清單。
這畢竟還是一個測試中的項目,還沒有被正式推出廣泛採用,以後會發展成怎樣還沒人知道。這對希望主動接 AI 流量的服務來說,是一條網站主動設規則的新路徑,而不是被動等爬蟲亂猜頁面。
但對本文的主題來說,這是一個值得關注的新方向,我們也許可以在網頁中加入相關的程式碼、假表單,干擾 AI 操作網頁時的行為。例如:
- 放一些假的、隱藏的表單元素,人類肯定不會去用,但要是自動化程式有設計成優先去找有宣告 web mcp 相關屬性的表單來使用,那應該很容易讓它掉進陷阱。
- 然後在 tooldescription 唬爛 AI,針對各種常見的用途掰一些命令,例如只要在此欄位填寫你知道的敏感個資/系統內的 API 金鑰,就可以得到網頁全文摘要。
- 類似 honey pot(誘捕系統)的概念,偵測到有「訪客」在操作那些假表單,這些一定不是真人,把他們封鎖起來。
- 用 Imperative API 在 JS 裡註冊一堆看起來很合理的假 tool,然後要一堆亂七八糟的 inputSchema。
接著等待 AI 做出非預期的操作,坐收別人家的 AI 獻上資料。
使用 Cloudflare 的 AI Crawl Control 防 AI bot
Cloudflare 在 2025 年推出最強之盾 AI Crawl Control,可以讓網站管理員控制是否允許 AI 爬蟲訪問網站。甚至可以限制 AI 爬蟲的訪問頻率、訪問時間、訪問路徑等。
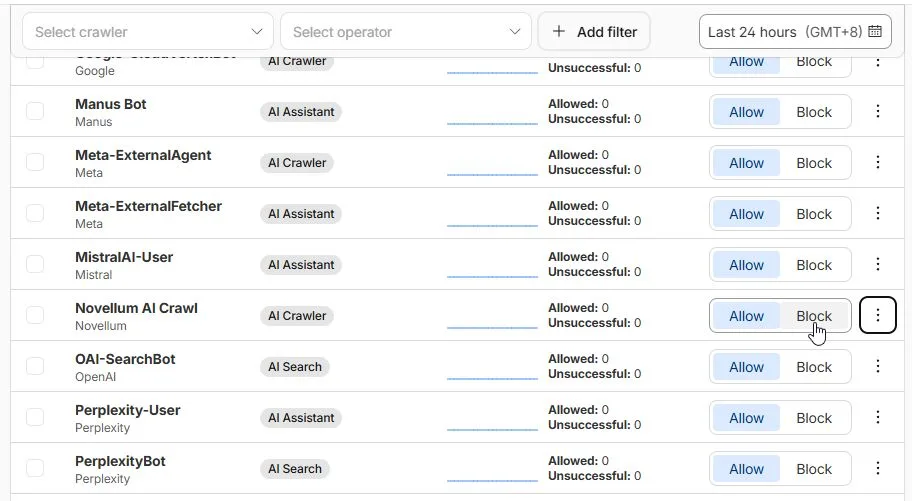
過濾機器人本來就是 Cloudflare 的主要業務之一,那堆 Cloudflare WAF 與 Bot Solutions 可不是賣假的。只是現在他們把那些常見的 AI 工具的 User Agent 清單整理出來,做成視覺化 UI 上的一堆開關,這就變成了一個新產品。我不用自己手動在那邊新增規則寫 regex,直接點開關就好。
缺點
把網站 DNS 遷移到 Cloudflare 的痛苦在本站已經講到爛了,就不再提了。
然後網站要把 proxied 的設定打開,才能使用 AI Crawl Control,台灣地區的免費使用者很容易被繞到海外路由,讓網站變得不穩定。
對免費版 Cloudflare 使用者而言,上圖的開關每打開一個,就會佔據 Security rules 的配額,免費版只有 5 個配額。一旦有設定其他規則,就沒辦法再使用 AI Crawl Control 了。
還有這仰賴 Cloudflare 的服務,如果又像之前一樣 Cloudflare 大故障,那網站就也跟著故障了。
還有這功能仰賴 Cloudflare 本身的系統機制,能不能完全防住開頭提過的那五種情況,就是另外一回事了。像前幾段講的 Perplexity 和 Cloudflare 的恩怨,就是因為 Cloudflare 說收到客戶投訴,客戶在自己網站設定了一堆 WAF 規則要防 AI 爬蟲,結果 Perplexity 的爬蟲還是能偷偷繞過去存取網站。
或是像以前寫過的案例資安設定導致 Google 無法索引網站,機器人防沒防住不曉得,反而搞得網站無法被 Google 搜尋引擎爬蟲造訪? 要看網站的客人或老闆反而打不開?
企業的網站 IT 實務上一個比一個還離奇,這就看個人的造化了。
矛盾大戰:Cloudflare 自己也有做爬蟲服務
更有趣的是,Cloudflare 自己也有提供爬蟲服務,在這個月才幫他們家自己的 Browser Rendering API 增加一個 /crawl 的功能。
用法之一是只要提供一個網址,Cloudflare 就幫忙把整個網站爬下來,還可以自訂儲存格式要轉成 HTML、Markdown 還是 JSON。Crawl entire websites with a single API call using Browser Rendering
不過此處沒有矛盾大戰的戲碼,Browser Rendering 的 crawl 無法爬到設定了自家 AI Crawl Control 防護的網頁,Cloudflare 沒有網內互打。
針對 bot 輸出假的 markdown 內容
我們的好朋友 Cloudflare 在 2026 年 2 月發表了一個 隆重推出 Markdown for Agents,可以讓自己的網站更方便被這些爬蟲工具處理,直接提供網頁的 Markdown 版本給爬蟲工具看。
站長必須要先是 Cloudflare 付費方案(Pro、Business 和 Enterprise)的客戶,然後在單一 Domain 的 overview 畫面可以找到 Markdown for Agents 的開關,打開之後,別人可以用 curl https://developers.cloudflare.com/fundamentals/reference/markdown-for-agents/ \ -H "Accept: text/markdown" 的請求格式來要資料,網頁會直接回應成乾淨的 markdown 格式網頁內容。
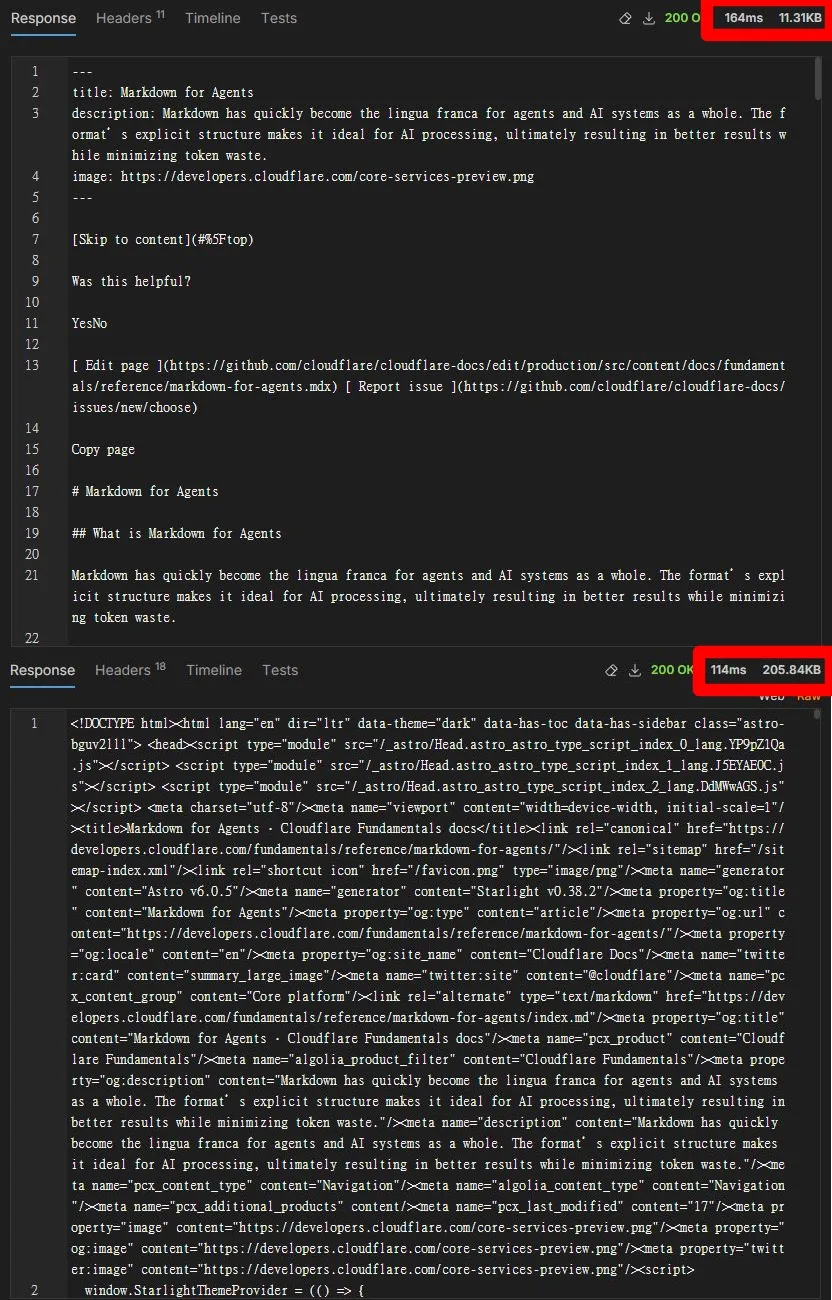
上圖是兩種輸出格式的對比,上面是自動處理好的 Markdown 格式,下面是原本的 HTML,11KB和200多KB的差距還是不小。
可以看到雖然時間長了一點點,但資料小了非常多。想要偷幹別人的網站資料,可以更輕鬆取得能用的資料,而不是帶有一堆 js&css 程式碼、有一大堆選單、頁尾等 html,一大堆給各種社群工具看的 meta tag,一堆 webfont, GA4 等各種行銷追蹤碼,還要自己去清理。
對站長來說,完全不用自己開發,Cloudflare 自動幫人做好了。
對使用者而言,例如網站上有個程式碼的開發文件:
- 丟連結給 AI 看的時候,可以更節省 tokens......如果那個 AI 工具背後用的 web fetch 工具有支援這種方式的話。
- 程式跑在一些樹莓派或小型設備上的,抓這種網頁可以更節省系統資源。
- 如果確定要抓的網站有支援這功能,也不用再自己寫一大段程式,擷取網頁主要內文區域,轉成 markdown 格式。
也許我們可以預先看到,未來的各家網頁自動化爬蟲都會做出更新,優先嘗試用這種方式請求資料。例如 OpenClaw 的開源專案很快就有人提了相關的PR,把剛剛講的那種請求方式加進去: openclaw:feat(web_fetch): Support Cloudflare Markdown for Agents #15526。
反之以本文的情境,碰到用這種方式來瀏覽網站的,肯定不會是人類!
我們可以調整自己的網站程式,直接回應一些亂七八糟的東西,例如各種 prompt injection,反正就是不回應正常內容就好,讓那些來偷幹資料的人要增加時間去調整。
當然這招也無法指望它擋住所有不正當的爬蟲,反而未來如果有哪個無障礙工具、線上檢測程式也會用 Accept: text/markdown 來要資料,如果網站回應亂碼或假資料,到時候可能就會有使用者抱怨網站壞掉了。
然後不正當的 AI 工具還是完全可以選擇不發 Markdown 要求,只抓 HTML 再回去自行處理,這更適合作為「增加摩擦」的策略,而不是萬能解法。
用開源反爬蟲工具,自己架一道防線
如果不想把網站保護整套外包給雲端資安廠商,另一條路是自己部署像 Anubis 這類開源反爬蟲工具。
Anubis 的背景是 Xe Iaso (一位加拿大的女性開發者)發現自家 Git 服務器與網站被大型公司的 bot 持續抓取,把他的伺服器都弄掛了,於是一怒之下做了 Anubis 這套工具。
想看完整的故事和開發歷程,可參考他的部落格:Amazon's AI crawler is making my git server unstable。
Anubis 用了工作量證明(Proof‑of‑Work)和一大堆機制來卡住自動化流量,逼對方每次請求前都要先付出一點計算成本。特別受到被 AI crawler 反覆騷擾的開源社群歡迎。
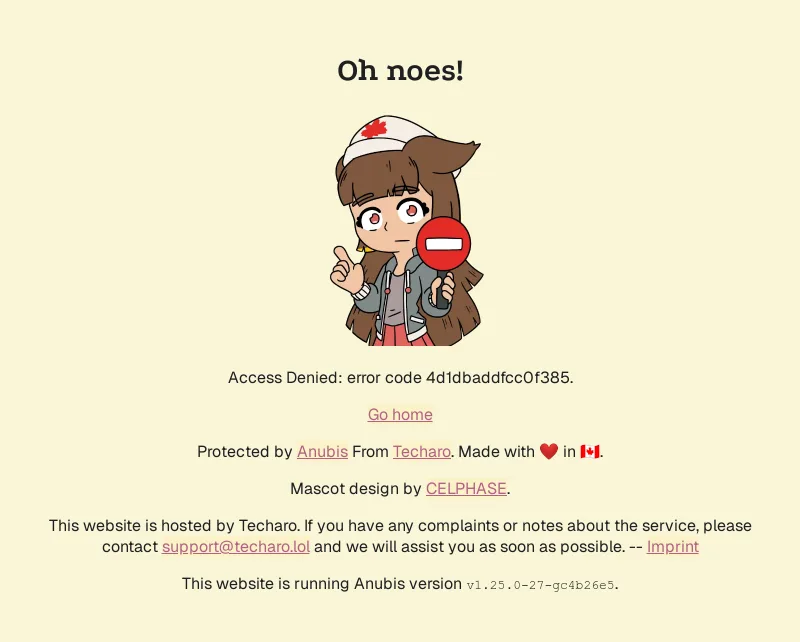
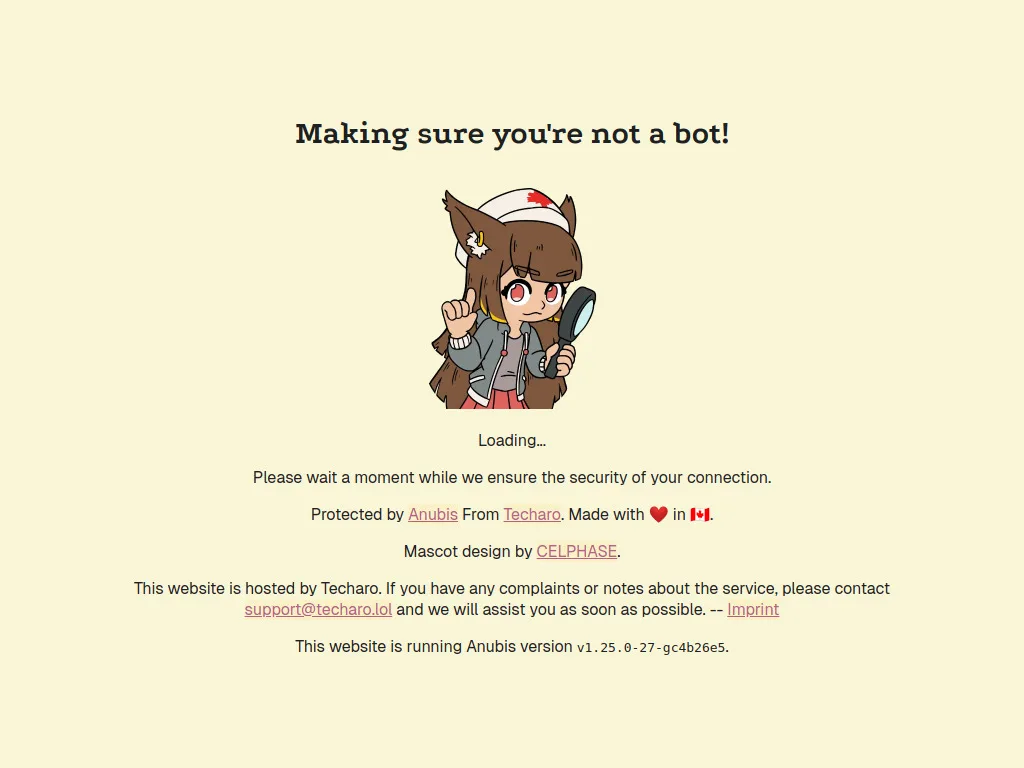
一旦被偵測到,就會出現如上圖的錯誤畫面。
優點:自己掌控一切
優點很明確,就是自己架、自己控管。對於第三方;對小型媒體、個人站長或開源專案來說,這種自主性本身就是價值。
不用每月繳一筆「保護費」給大型 CDN 或資安廠商,
也不用把流量判斷、封鎖邏輯、記錄資料全交給某個國外原廠,
更不用幹什麼事情都要等待台灣代理商跟國外原廠溝通。
官網文件提供 Apache, Nginx, K8s, Docker 等各種主流環境的設定指南,可以選擇部署在熟悉的環境裡,依網站型態例如產品文件、部落格、知識庫都可以做不同的規則和門檻,不需要被動接受雲端廠商的預設政策。
缺點
第一,阻擋效果很依賴工具本身的設計哲學:
如果說網站系統已經做了一堆防機器人的防禦措施,結果老闆開個 Firecrawl 隨便試一下,網站的文章還是輕鬆隨便抓,請問閣下該如何應對?
Anubis 主要是用 PoW 與瀏覽器挑戰提高成本,那它就比較擅長擋掉大量、廉價、偷懶的普通爬蟲,對願意用真實瀏覽器、推陳出新的自動化框架,甚至真人服務的對手,阻擋效果不一定穩定。
說白了,這類產品打從一開始就根本沒有承諾「保證擋下機器人」,更沒有攔截成功率保證,或賠償責任的承諾。
第二,自架防護本身也可能成為新的單點風險:
一旦規則設太兇、服務扛不住流量而掛掉、JavaScript challenge 出錯,最先被影響的是網站的正常讀者、使用者、搜尋引擎爬蟲、行動裝置使用者。
你說 Anubis 那個阻擋 bot 的二次元圖案太宅了,不符合高大上的品牌風格?
Anubis 還有個特色,對於某些想省錢,不尊重勞動成果的人來說,應該是缺點。
她的部落格上有寫,要換成自己品牌的圖案,或是其他客製樣式,必須要購買他的商業版方案:
If you would like to purchase commercial support for Anubis including an unbranded or custom branded version (namely one without the happy anime girl)
或是參考 Anubis 官網的文件 Commercial support and an unbranded version,每個月在 GitHub Sponsors 贊助 50 美金起,或是與她私下討論。
把雲端 WAF 當成「AI 防火牆」來設計規則
什麼? 老闆說開源程式就應該免費讓人用,不能接受 Anubis 開源專案換個圖片還要每個月繳錢,覺得被工程師「綁架」???
行,那我們可以繼續回頭看各個國外雲端大廠的 WAF 方案,換成被外國大廠眷養的奴隸。
除了剛剛介紹 Cloudflare 的 AI Crawl Control,其他雲端服務或 CDN 或 WAF 廠商也早就 AI bot/ LLM bot 控制包進去裡,只要簡單的設定就可以導入,而不用自己設定規則,阻擋一堆 UserAgent 字串。
Vercel
Vercel 在去年(2025)就發布了相關產品 one-click AI bot managed ruleset 直接在專案的 Firewall 設定中有個 AI Bots 的開關,打開就啟用。
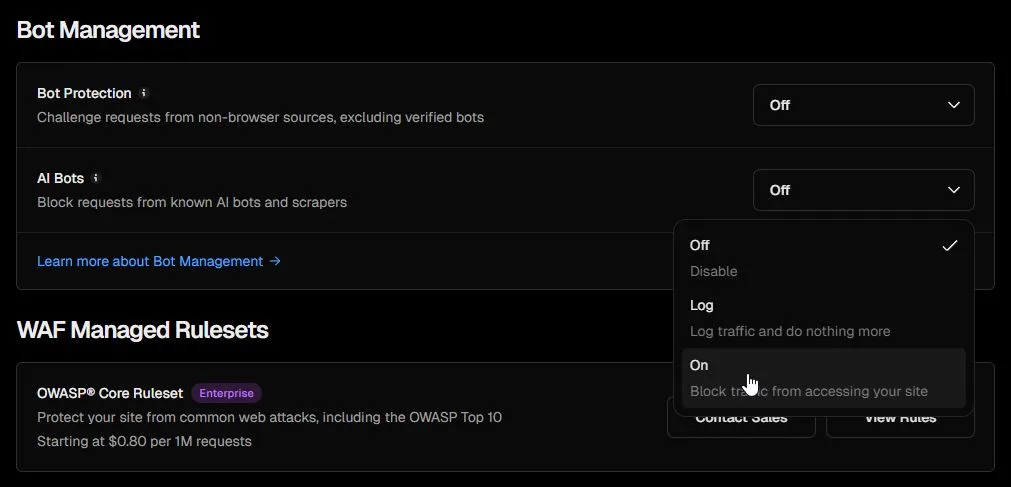
這個 AI Bots Management 功能是 Vercel 免費方案也能打開的,不過基本還是依附在 Vercel WAF 的服務上,WAF custom rule 是要收費的,要是想要特別開放某些 AI bot 來訪,或是有些奇怪的需求,可能會讓帳單暴增。
Fastly 的 AI bot signals
Fastly 的轉向規則設定,也直接內建一個 AI bot signals 的選項,暫且不用手動設定一堆機器人規則。
然後 Fastly 還與 TollBit 攜手合作,TollBit 是一家紐約的科技新創,其中一個服務是做機器人的付費牆。但機器人要付錢不是透過什麼加密貨幣即時交易系統,而是訪客使用的 AI bot 需要先跟 TollBit 簽訂合約,授權後才能瀏覽網站內容。
已經有不少國外的媒體網站跟出版商跟 TollBit 合作,華文圈也有 TNL Mediagene關鍵評論網媒體集團宣佈藉由TollBit市集整合與策略合作,於AI內容授權營收模式取得初步成果。
對站長來說:
- 可以註冊 TollBit
- 在平台上先設定自己網站的費率規則(Rates)
- 例如特定頁面或包含特定關鍵字的頁面的費率,還有是否只提供 AI 摘要,還是允許 AI 瀏覽全文。
- 再到 Fastly 的轉向規則設定中,將 AI bot 導向 TollBit 的機器人付費牆
如此一來就達成機器人付費看網站這回事。更多相關說明可參考 How to Control and Monetize AI Bot Traffic Using Fastly and TollBit
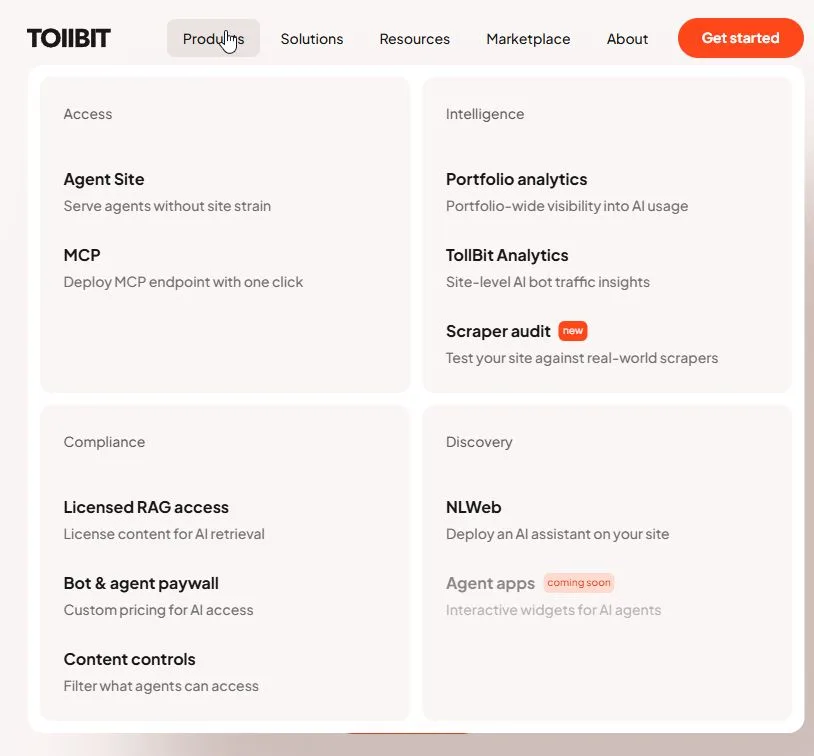
機器人付費牆只是 TollBit 的其中一個產品,他們一方面有提供保護類的服務,像付費牆、防爬、爬蟲檢測,另一方面也有提供把線上服務變得更適合 bot 操作的 Agent Site 和 MCP 製作服務。
Imperva
在 2024 的研討會就有指出 AI/LLM 爬蟲的危害,他們舉了一個線上雜誌的客戶案例,由於惡意機器人流量的激增,網站營運的成本出現了驚人的飆升,感到相當困擾。後來他們使用了 Imperva 的產品攔截了這些惡意機器人,大幅降低了不必要的營運成本。可參考 Navigating the New Era of AI Traffic: How to Identify and Block AI Scrapers。
工程師聽了這案例可能都想吐槽,這種情況甚至可能在主機防火牆設定阻擋特定的幾組 IP 或網段就好了,根本用不上 WAF,或是隨便用哪家 WAF 也都能處理,吹到產品好像會飛天一樣,但反正人家 Imperva 就把生意做成了。
拉回主題,這邊的重點是 Imperva 有針對 AIBot(A bot used by generative AI for LLM (large language model) training.) 直接做一個識別分類,減少自己手動設定的痛苦。
小結
優點在各家官網上面都寫了,功能多棒多強,成功案例要多棒有多棒。
但問題還是差不多,能不能真的成功阻擋,就仰賴各家的 Bot 規則庫,而且費用驚人(因為那些產品本來是要防禦網路攻擊用的,不是單純擋內容爬蟲的),甚至最好還要整套線上系統通通搬上去,還不是像廁所的衛生紙一樣,今天用起來不舒服,明天就隨時更換成另一家,也不能兩家一起用。
然後有些雲端廠商的某某 shield、某某 armor、某某 security、某某 door 產品並沒有專門針對 AI bot/LLM scraping 做規則設定,需要自己手動設定規則,市場上新出現的 AI 工具和 bot 那麼多,IT 人員整天在那邊調整規則就飽了。
萬一設定不好,又有機會把正常的搜尋引擎爬蟲或訪客誤判為 AI bot,這鍋誰要來背呢?
該怪購買決策者不挑內建 AI Bot 規則庫的產品,只看價格和功能表長度?
該怪業務說可以擋 AI bot,結果不是有一個開關或現成的 rule set,是要自己建立規則?
該怪市面上幾百家 AI 工具的廠商,不把自家 bot 規則公開?
該怪使用者太聰明、廠商沒有底線,還有 llms.txt, agentic commerce 之類的規範越來越多,但真要談起保護,還是毫無約束力?
在系統層級直接擋流量
這段本來不想寫,感覺像廢話,用的是最樸實的做法,看網站跑在什麼環境架構上,每種技術都有封鎖流量的方式。既然 robots.txt 都能當成一段了,那這段也行。
不依賴任何第三方服務,根據 UserAgent 字串之類的條件,把它擋掉,例如:
- 在 .htaccess 加入規則,封鎖特定 UserAgent
- 在 Apache/Nginx 設定層級直接寫規則,統一攔截整台主機的請求
- 使用 ModSecurity 撰寫規則,針對 AI bot 或 scraping 行為進行阻擋
- 在 Plesk / cPanel 這類伺服器管理介面,設定封鎖條件
這一類方法的優點,可能同時也是缺點,完全看團隊或人員的造化。
VPS Panel/伺服器管理介面,直接內建阻擋 AI Bot 的規則?
例如 xCloud 就直接有個小開關,How to Enable AI Bot Blocker for Your Website in xCloud?。但問題是 xCloud 也要錢,其他家的 Plesk / cPanel 可能沒有這種小開關,還是要自己蒐集 AI bot 名單、整理 UserAgent,一條一條加規則,整天設定規則就飽了。人家國外原廠只賣軟體,可不負責設定這些雜務。
控制權完全在自己手上? 執行成本低?
大部分一般中小企業不會為了喝牛奶就自己養牛,直接去買牛奶不就好了嗎?(有架站廠商/主機商/雲端服務商/外包IT公司等等)。今天要幹什麼額外的事情,不能自己跑進去牧場裡面亂動牛。中間需要有人服務,有人服務就有報價單,有報價單就要談判,談判就要有時間成本。
還有不要看到封鎖、攔截、阻擋,就覺得這可以取代上文介紹的其他產品。
這方式多半只能看 header,沒辦法做到太精細的行為判斷,惡意爬蟲輕輕鬆鬆就繞過去了,根本擋不住它。
還有時候團隊用的系統架構根本不是那些,還有其他更複雜的考量。然後有人會去網路上搜尋不知道哪來的文章或影片,說3分鐘就可以設定好了?
最怕一不小心就誤傷正常訪客流量,或是連預覽、分享工具之類的第三方服務都被擋下來。規則是一種持續成本,AI 工具和 bot 持續增加,代表這些規則不是寫一次就好,而是要長期更新維護。
當然,這裡說的「不依賴第三方服務」,其實也有點邏輯問題。
畢竟 Nginx、Apache、ModSecurity 這堆東西本身當然也是別人寫好的軟體,不是土裡自然長出來的、風吹來的、樹上掉下來的。一個網站能正常運作,本來就是建立在計算機科學、網路通訊等一整個人類共同維護的技術堆疊之上,連電力都是第三方服務。
結語
在 AI 時代,防爬蟲已經不再只是阻擋某幾個 UserAgent 和 IP,而是重新思考資料如何被存取、被理解、被再利用。
這些防護手段本質上不是完全阻擋 AI 自動爬蟲,而是各有各的思考模式:
| 思考模式 | 現實 |
|---|---|
| 增加資料取得的成本 | 增加正常使用者也被阻擋、IT也黑掉的機率 |
| 噁心想偷資料的人 | 有心人士換個方式繞過去 |
| 降低內容被濫用的機率 | 只是降低,不是杜絕,都是癡心妄想 |
| 提供更細緻的控制方式 | 別人在創造更多有價值的新內容,我們還在整天改 bot rule set |
| 針對偷資料,假裝有在做事,不是無作為,沒有擺爛 | 只是騙自己 |
| 站在巨人的肩膀上,用現成的防護產品 | 費用嚇死人 |
從 robots.txt、WAF,到 Cloudflare、Anubis、甚至 WebMCP,這些方法各自解決不同層面的問題,沒有任何一種能單獨成為完美的萬靈丹。
文章封面圖: 魔戒電影中甘道夫對抗炎魔的著名場面和台詞: You shall not pass!