
電商後台真正需要的是 MCP 和 Skills,別在網站後台到處塞 AI 魔術棒按鈕了
去年到今年開始看到相同慘業的幾個有名的大頭 Shopify, SHOPLINE, WordPress,不約而同在產品中加入各種 AI 串接功能,不只是提供各種 API,還有 MCP、CLI 之類的。
我嘗試模仿那些功能概念,也在自己的產品中加入這些玩意後,深感驚豔。

在某些情況下,這是一個雙贏局面:
- 使用者操作起來明顯更順手,直接在 ChatGPT 之類的 AI client 工具內把事情做完,原本有許多繁瑣、對品質要求不高的工作,現在能透過自然語言或 AI Agent 快速完成。
- 對 CMS/電商系統/筆記軟體...等各種數位資料管理工具的開發團隊來說,也彷彿打開了一條新的出路,是讓系統開放給 AI「使用」,不再是不斷堆疊沒人用的後台功能、每天斤斤計較客人的 AI tokens 又花了多少錢。把轉賣 AI token 的腦力,繼續回到開發產品上。
新的做法當然也帶來了新的問題,從開發到營運,迎來了更多新的系統管理與架構挑戰。
傳統系統的困境
在當今的線上系統開發中,許多電商網站與 CMS 系統功能越做越專業,卻也越做越讓人痛苦。開發人員花了大量時間堆砌老闆覺得應該要有、使用者覺得應該要有的功能。
對程式開發人員而言,程式碼不是資產,而是負債,今天跑得好好的程式,明天就可能因為更新一下 OS, web service, database 或執行環境或相依套件,或是調整了一些系統設定,某個上游遭遇供應鏈攻擊,造成系統問題,而打亂原本的工作安排。
對使用者而言,系統中的功能越來越複雜,但永遠少了想要用的那一個。
讓人密集恐懼症發作的資料篩選器
後台管理介面裡,訂單、會員等各種資料列表頁,已經塞了二三十個篩選條件,但還是有永遠加不完的新選項,永遠開不完的功能討論會議,幾個禮拜後,沒人想得起來那個選項是幹嘛用的。沒人知道哪幾個選項組合起來,又會爆出 500 error。
永遠會有無法涵蓋到、無法「一鍵產生」的查詢條件,接著便是一些對岸互聯網黑話,什麼數據中台、強調要打通任督二脈,沉澱能力,拉通全鏈路,形成一盤棋。要顆粒度對齊、口徑一致,避免數據孤島,抽象到模型層,賦能前台業務,降維打擊。要構建資產閉環,穿透到底,打標打透,精準觸達,形成閉環再反饋,最終上收下放,靈活調度,持續造血。
將網站系統變成 MCP server 後,解決了哪些使用者的問題:
- AI Agent 可以直接透過自然語言提出複雜查詢(例如:「找出上週二到週四、台北市、客單價 > 800、買過 A 沒買 B 的用戶」),無需再依賴固定的篩選器 UI 。
- 讓 AI 使用 MCP Server 設計好的結構化工具,動態組合查詢條件,讓 LLM 過濾出使用者想看的資料,大幅減少 UI 複雜度。盡量避免窮舉所有可能的組合並做成 UI 選項。
- 不用再為了更細的資料,開發團隊繼續製作讓人密集恐懼症發作的操作介面。後台依然維持輕量,AI 成為「智慧查詢引擎」。
長期來看,部分後台 UI 大幅簡化,只保留常用操作,進階分析全交給 AI 處理。
到處都是魔術棒?
有些系統為了展現「我的產品有 AI」,在幾乎所有輸入文字的地方、插入圖片的地方,都加上了一個閃亮的魔術棒按鈕,只要點下去,就能呼叫 LLM 生成商品描述、行銷文案、留言回覆、瞎掰頁面上的企業理念、插入不知所云的 AI 圖片。
然後還要搞得跟手遊一樣,設計一堆「AI點數」銷售方案,他們可能昧著良心,接一些來路不明的便宜中轉 API,有什麼問題都甩鍋說是 AI 的問題。
也可以花很多心力,找各種成本勉強能負擔、好用、又號稱安全的國內外 LLM API,做了 prompt 工程、做了對話記憶、相容各家的 LLM API 資料格式。
結果上線後,使用者只會說:「還是直接用 ChatGPT Plus 比較好用,一個月才 600 多塊。」於是系統中的魔術棒變成了裝飾品。工程師和產品設計師越努力把 AI 塞進系統,使用者就越覺得「為什麼我要在你們這裡用一個又貴又笨的 AI ?」
更麻煩的是,只要把 AI 功能做進系統裡,使用者就不會覺得那是 OpenAI、Anthropic、Google 或哪一家上游 AI 模型供應商的問題,而會覺得是系統壞了。
當上游的 AI Provider 全球大當機時,系統內那些 AI 魔術棒功能就掛了。OpenAI 都不可能給工程師補償,反倒是使用者來要補償了?
系統開發者不只要維護自己的程式,還要被迫扛起上游模型穩定性的期待。API timeout、quota 用完、模型回應變慢、供應商改價格、內容安全策略變嚴、某天 AI 突然拒絕回應。使用者不會想理解這些細節,只會看到:昨天還可以用,今天不能用。
更可怕的是,功能可以修,內容責任更難切割。
如果使用者拿系統裡的 AI 產文功能,產出一堆爛到不行的 SEO 垃圾文,甚至直接叫 AI 抄襲改寫別人的文章,長期讓整個網站內容品質變差,跟那些 pSEO 的玩家一樣,哪天突然整個網站從 Google 中不見、品牌調性變廉價了、文章被檢舉處罰了,使用者不會承認是自己亂用 AI。
很可能會反過來說:網站本來好好的,就是用了系統內建的 AI 產文功能,排名才開始掉。只要 AI 功能是系統裡的按鈕,使用者就會自然把結果和產品綁在一起。
將網站系統變成 MCP server 後,解決了哪些使用者的問題:
- AI(Claude、ChatGPT、Cursor, Perplexity 等)能直接連接到我們的電商系統、官網文章系統,取得即時、真實的上下文資料(商品、訂單、庫存、歷史發文等),而不是生成空泛文字、每次幹什麼事都要人類複製貼上資料給 ChatGPT。
- 生成的內容品質大幅提升,因為 AI 不是憑空想像,而是能真正看到資料、直通系統,透過 mcp 或 skills 開放出來的業務規則來工作。
- 使用者不再需要硬是用一個網站系統商為了節省成本,而做出各種限制的「弱化 AI」,而是可以直接在自己熟悉的 AI 工具(ChatGPT、Claude Desktop 等等)呼叫網站的 mcp server,體驗遠勝於封閉的魔術棒。
- 工程師不再需要自己維護 LLM 整合問題與鑽研各種 prompt 工程,專注做好 mcp server 即可,讓外部強大 AI 成為系統與使用者的延伸大腦。
- 上游 AI Provider 的穩定性責任跟網站系統商無關,不必替上游模型的當機、幻覺、內容品質與生成結果,背全部的鍋。
- 內容品質的責任也比較容易切開。網站系統開發端回歸本質,負責提供「資料編輯工具」。至於使用者要用哪個 AI 模型、下什麼 prompt、生成什麼風格的文案、要不要大量產生垃圾內容,這些是使用者在自己 AI 工具中的操作選擇,而不是網站系統商內建 AI 功能直接產出的結果。
付費牆正在崩壞?
SaaS 產品最常見的變現思維是:把常用功能拆成基礎版,把真正好用的進階功能藏在付費牆後面。例如:
- 通知預設只能寄 Email,其他通知方式(Slack、LINE、簡訊、Webhook)要付費升級到什麼天龍地虎方案才能用;
- 付費版才能「批次一鍵全選 + 一鍵執行」「排程自動化執行」,普通版要點好幾下,在好幾個頁面之間切換。
- 宣傳頁面上有一堆吸引人的功能,先把客人騙進來,然後那些都是高階方案才有。
產品經理心想:這樣就能好好變現了。但現代的現實是:
- 有概念的使用者,只要把需求丟給 Claude 或 ChatGPT,幾分鐘就能生成一段 Google Apps Script 把通知郵件發到任何地方去。
- 寫一個簡單的 Chrome Extension,就能做到原本要付費升級方案才能做到的事。而且這些自製工具還更靈活、不用每月付訂閱費、不會擔心廠商說下個月起要買什麼方案才能用那個按紐。
- 找像我這樣的外包臨時工,做一個要跟某某某差不多,但是有一些「小地方」要調整的系統。
原本產品設計用來綁住我們的資料、維持產品營運的收費功能,變成了使用者逃離系統的催化劑。
將網站系統變成 MCP server 後,解決了哪些使用者的問題:
- 使用者可以直接用 AI 撰寫更強大、更靈活的自動化流程 Agent,而這些自動化是建立在系統商第一手的 MCP 工具之上,不用再繞過系統。
- 付費模式可以從「鎖功能」,轉向提供更好、更安全的 MCP 存取權限、更高額度、企業級工具、稽核紀錄等更高價值服務,使用者更願意付費取得官方、穩定、安全的 AI 整合能力。
- 降低使用者自行開發腳本的動機,因為透過 MCP + AI 的組合已經足夠強大且方便,同時減少因自製腳本帶來的資安、相容性、維護問題。
那些永遠串不完的外部服務
傳統系統還有一個很煩的困境:使用者永遠會希望網站能跟更多外部數位工具串接。
今天客人說,希望訂單資料可以自動同步到 Google Sheets,方便他自己做報表。
明天又說,希望網站可以讀取 Google 雲端硬碟裡的檔案,讓編輯不用每次手動下載再上傳。
過幾天設計師又希望後台可以讀取 Figma 設計稿,直接把設計稿做成網頁。
再過一陣子,行銷人員可能又想把資料丟到 Notion,或某個下個月就不想用了的雲端工具。
這些需求單獨看起來都不大,vibe coding 一下就做出一版 demo。但問題是,網站就這樣慢慢長出一堆一次性的外部串接程式。當初寫的人覺得只是「幫客人接一下」,幾個月後就變成沒人敢動的歷史包袱。Google API 改版、Figma token 失效、某個雲端服務改了 OAuth 流程,Google 帳號哪邊動到設定,原本好好的功能就壞掉。
只要有資料傳輸,就一定要處理驗證。
只要要處理驗證,就得在專案某個地方保存 access token、API key、client secret 等各種東西。
這些東西可能被塞在資料庫、環境變數、設定檔、某個沒人記得的後台欄位,甚至是工程師當年為了趕時間先硬寫在程式裡。時間一久,沒人確定哪些金鑰還活著、哪些權限開太大、哪些外部服務還有人在用。
金鑰越多,驗證風險越多;
程式越多,資安稽核問題越多。
原本只是想讓網站「方便一點」,最後卻變成專案裡多了一堆不知道誰負責維護的外部依賴。
每多一支同步程式,就多一個排程失敗點、多一個權限外洩點、多一個 API quota 問題,也多一個未來可能壞掉的地方。
MCP 出現後,這件事的責任邊界開始有點不一樣了。
如果網站後台本身提供 MCP,讓 AI 可以安全地查詢商品、建立文章、更新頁面HTML&CSS、取得訂單摘要,那很多「幫我把 A 系統資料搬到 B 系統」的需求,完全不需要由網站自己硬串每一個外部服務。
使用者可以直接在 ChatGPT 裡同時連接網站的 MCP、Google Drive、Google Sheets、Figma 或其他工具,讓 AI 在它自己的工作環境中完成資料整理與搬運。
換句話說,網站不一定要為每個客戶、每個外部服務、每個臨時工作流都寫一支專用串接程式。網站只需要把自己的能力用 MCP 開放出去:
哪些資料可以讀、
哪些內容可以寫、
哪些操作可以執行、
哪些權限不能碰。
至於要把商品資料整理到 Google Sheets、從雲端硬碟讀取素材、參考 Figma 設計稿產生活動頁文案,這些跨工具流程,就交給使用者自己的 AI 工具去組合。
這聽起來有點像把麻煩轉嫁給 ChatGPT,某種程度上也確實是這樣。以前是網站系統要負責串接全世界,現在變成 AI client 負責連接各種工具,而網站只要把自己變成其中一個可被呼叫的工具。
當然,這不代表網站端就完全沒事了。網站還是要做好 MCP 權限控管、操作紀錄、rate limit、資料遮罩和錯誤處理。但至少它不用再為了每個客戶的臨時奇想,在專案裡長出一堆不知道能活多久、也沒人願意維護的外部串接程式。
那些大廠的 MCP 做了什麼
我先不要一上來就戳破大家的好夢,不講實際上有什麼問題。也先不談程式碼實作或現實問題,先來看看那些大廠的 MCP 做了什麼。
主要就是讓 AI 直接得到第一手資料,降低幻覺發生。
降低幻覺發生
降低幻覺發生
降低幻覺發生
很重要說三遍。
還有直通系統功能,減少人力在 ChatGPT 跟網頁系統之間互相切換,剪貼資料的情況。
WordPress
WordPress 6.9(2026 年初):引入 Abilities API,這是 MCP 的重要基礎。允許 plugin、theme 和 WP Core 去「註冊」自己的能力(Abilities),讓 AI 可以發現並呼叫。
WordPress 7.0(預計於 2026 年中發布,時程一延再延):把 Abilities API 更穩固地整合進核心,並正式加入 MCP Adapter(官方 MCP 轉接器)。這讓Claude Desktop、Cursor、ChatGPT 等 AI 工具可以更順暢地發現和使用 WordPress plugin/theme/主程式的功能。
以前如果我要讓 AI 做一個 WordPress 自動發廢文的腳本,還要先整理 WP REST API 清單,把發文章、傳圖片到媒體庫等一堆操作究竟需要打哪幾支 API,用什麼資料格式搞清楚,然後做出程式。
在 WordPress 6.9,要安裝官方出的MCP Adapter,然後完成基本設定
"取個名字": {
"command": "npx",
"args": ["-y", "@automattic/mcp-wordpress-remote@latest"],
"env": {
"WP_API_URL": "https://網站的網址/wp-json/mcp/mcp-adapter-default-server",
"WP_API_USERNAME": "使用者名稱",
"WP_API_PASSWORD": "應用程式密碼"
}
}
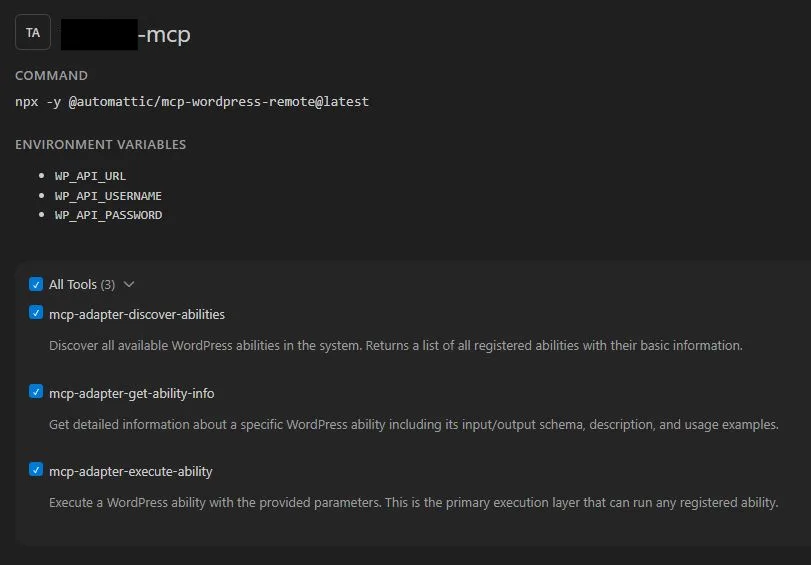
再透過 AI 呼叫 MCP,就能看到目前網站安裝的套件註冊了那些 mcp tool,並使用他們。

也可以再自己透過 mcp_register_ability 註冊一個新的技能給 AI 使用
mcp_register_ability(
'wp-core/create-post',
[
'label' => '建立新文章',
'description' => '在 WordPress 網站中新增一篇新文章。',
'input_schema' => [...以下省略
可以參考官方文件 wp_register_ability。
在某些用途下,以前那些搞了一堆 WP REST API 的程式簡直就是笑話。但還是可以讓一些 WordPress 無法升級的網站用,或是在 n8n 之類的工作流工具復刻一遍。
SHOPLINE
在上個月(2026年4月)的時候,台灣的 SHOPLINE 粉專發文介紹他家的 MCP。
去查了一下文件,官方的 MCP 主要是 SHOPLINE Developer MCP,目的是幫助開發者與 AI 更快理解和使用 Shopline 的 API,用來快速查文件、產生正確的 API 呼叫範例,降低幻覺發生。
而不是直接做讓店家新增商品、改訂單的 mcp tool。
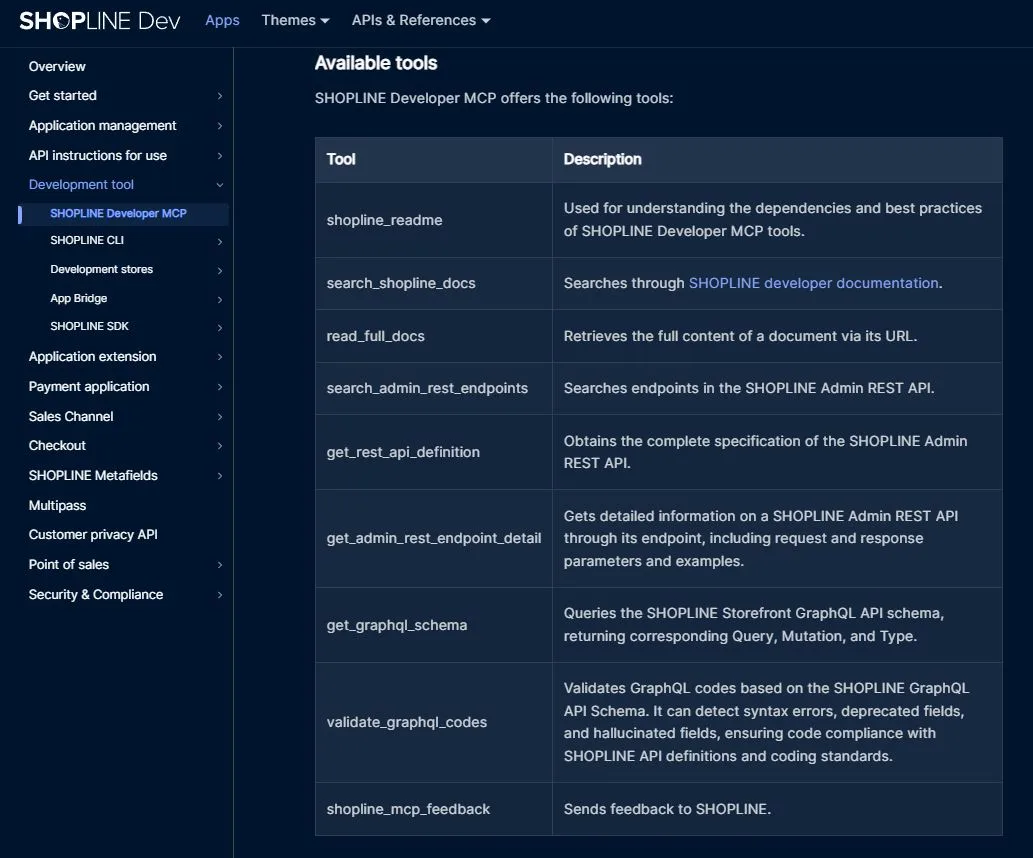
看起來有點像 SHOPLINE 把本來就有的 Open API 再套層殼,讓 AI 可以更容易使用,而不是讓系統可以無中生有,憑空產生新的功能。
如果用這個 Open API 套殼的概念出發,那我們也可以很快找到其他第三方的套殼廠商,例如 Asgard-ai 的 mcp-shopline。
不過我記得 SHOPLINE 的 Open API 是要再另外購買才能開通的,每年要額外再付幾萬塊。反正大家就記得 SHOPLINE 的 MCP 只有什麼功能,不要聽到就自己嚇自己。
Shopify
在台灣的低成本開電商的圈子可能不是這麼流行用 Shopify,那種免年費的電商平台更有名,畢竟 Shopify 最陽春的版本每年也要台幣幾千塊起,而且能用的台灣金流物流都有限。但畢竟 Shopify 是美股上市公司、慘業龍頭,產品生態系不可忽視。
Shopify 做了一些給消費者使用的 Storefront MCP 和 Customer Accounts MCP server
。
我隨便在網路上找了個用 Shopify 系統的台灣電商來測試,因為同一平台的 mcp 的路徑都是標準化的,就算網站沒說自己有這功能,知道門道的人還是可以很輕鬆偷連上去。
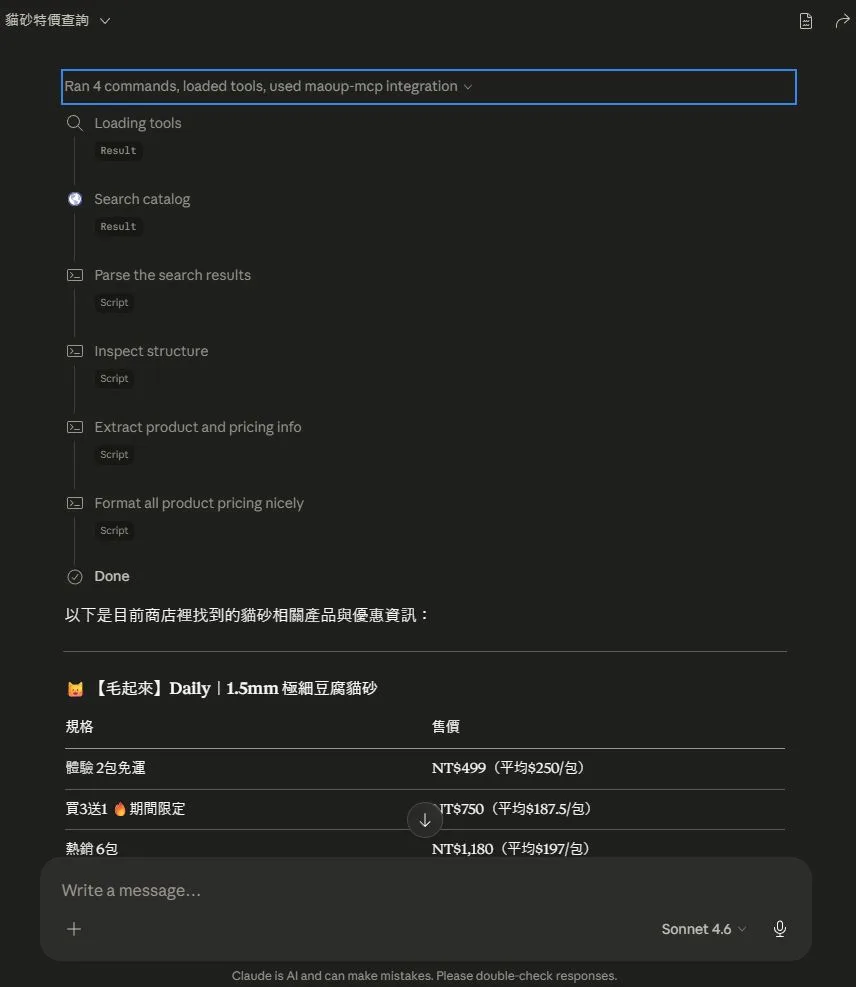
上面式我裝起來測試的範例,找最便宜的商品,平常 AI 碰到使用者丟出這種需求,通常是先用 web search tool 去找網站,然後用 web fetch tool 把網站內容抓下來,經過各種處理後產生回答,就算中途任一環節出問題,AI 還是會一本正經的胡說八道,大家也深信不疑。這下透過 MCP 則是直通商品資料,速度更快,準確度更高。
當然這不只是消費者拿來快速查商品資料、比較商品。如果慘業工作者要做競品分析,不用每天照三餐 F5 看人家網頁上有更新什麼商品,不用自己寫爬蟲程式,只要用 ChatGPT 的 Task 定時任務之類的功能也能辦到。
Shopify 另外還有一套給開發者使用的 Dev MCP server。
如果只論店家編輯人員管理電商網站資料,同樣有一堆第三方廠商開發的 Shopify MCP Server,Shopify 還有跟 Claude, OpenAI 開發的應用程式。
Emdash
Cloudflare 在上個月(2026 年 4 月)推出的新開源 CMS,目前還在開發預覽版。Introducing EmDash — the spiritual successor to WordPress that solves plugin security
官方文章標題直接就跟 WordPress 對幹,但是一般使用者看到產品 demo 後台,大概只會覺得這是 10 年前的 WordPress 編輯介面,也沒有區塊式功能,實在不懂 Emdash 有什麼臉出來嗆聲。
外行看熱鬧,內行看門道,如果是沒什麼人來逛的網站,用 Emdash 架在 Cloudflare 的成本甚至有可能趨近於免費。還有 Emdash 的外掛隔離式設計也是非常特殊,以前要是提供這種設計大概只會被人當白痴。
Emdash 最大的特色是強調 AI-native,AI 可以直接管理整個網站,適合那種適合需要大量 AI 輔助內容創作與管理的團隊(怎麼聽起來這麼像生產網路垃圾的內容農場?)。
MCP/CLI/Skills,要開發哪一種給使用者使用?
為啥不讓 AI 直接接 API 就好,慘業又要憑空發明幾種新的格式,主要還是協議層面的標準化問題。
從上面案例我們見識到了一些可能性,這不是傳統那種做個 API 給人用,然後兩邊的工程師整天在爭論狀態碼、資料格式、API 文件維護等等問題。
要讓 AI 能「使用」網站後台,最常見的選擇有三種方式:MCP/CLI/Skills,各有各的優缺點。
MCP(Model Context Protocol)
MCP 是目前最主流的標準,一開始由 Anthropic 在 2024 年底提出,可以讓 AI 直接存取目標資料。有 SSE (Server-Sent Events)、JSON-RPC over Stdio、JSON-RPC over HTTP 三種傳輸方式。
本文實作主要是 JSON-RPC over HTTP 這種的,最接近一來一回的 web api,而且最適合本文討論的應用場景(店家透過 AI 幫忙管理網站),其他種比較適合完全沒有網路連線,或是要一直跟伺服器保持不斷線的使用場景。
MCP 簡單來說就是多寫一套程式,用 jsonrpc 接收各種規範好的 method 請求,例如 tools/call、tools/list、resources/read、initialize、prompts/list 等等,還有處理每個請求帶上的參數(params)。
在 tools/list 中要定義每個 mcp tool 的 inputSchema。在 initialize 中要定義 instructions 等各種基本資訊,告訴 AI 這個 MCP server 的用途。
然後讓 AI 看那些 instructions 而望文生義,自己知道調用哪個 tool,以及生成呼叫 tool 需要什麼參數。
Skills(Agent Skills)
Agent Skills 又是 Anthropic 在 2025 年 3 月提出的標準,用來讓 AI agent 能夠使用各種技能,在技能包中會有一些定義技能的 md 檔案跟提示詞檔案,還可以放入各種 python 跟 php 檔案,用來輔助執行。
近來一些套件的官方廠商都會提供官方自己出的 skills,讓 AI agent 可以更方便使用他們的功能。
例如 Greensock 的 GSAP 有 gsap-skills
Sentry 也有Sentry for AI - Agent Skills
順豐也有把他們的 Open API 做成MCP&Skills
綠界有提供ECPay API Skill
當然這並不是幫自己的 AI 軟體裝上 Skills 之後就能馬上完美達成任務,例如順豐的台灣寄台灣,要先知道自己要串的是順豐的哪一套 API,然後還要知道 API 的申請流程和開通流程,帳號身分的區別,哪些功能還要人工另外申請,哪些結果要再自己轉繁體才能顯示,不然生成了程式碼不能用,使用者還以為是 AI 的問題。
本文討論的網站後台管理MCP,比較不是「讓 AI 幫忙寫一段串 API 的程式」,而是「讓店長或編輯直接在 ChatGPT 裡修改網站資料」。所以我這次沒有另外做 Skills,而是把重點放在 MCP Server。未來如果要把這套東西做得更完整,Skills 也可以變成 MCP 的說明書,負責告訴 AI 哪些任務該怎麼拆、哪些 tool 該怎麼搭配、哪些操作要先查詢再寫入。
不過說到底,不管是 MCP 還是 Skills,都不是把文件丟給 AI 就會自動變聰明。真正麻煩的,還是要把那些人類平常靠經驗、靠文件、靠客服、靠前輩口耳相傳才知道的規則,整理成 AI 看得懂、用得對、不容易搞壞資料的形式。
CLI(Command Line Interface)
嗯...CLI 就是 CLI,在電腦上安裝程式和註冊變數之後,就可以在命令列(terminal)中直接使用。可以輸入指令來執行程式。AI 就是透過生成指令和接收指令的回應結果,在某些使用場景下,可以用更高的效率來操作程式。
例如一些 WordPress 的管理操作,還要裝一些付費套件、在 UI 上點老半天? 有些就是 WP CLI 下一些指令就能處理的。但是一般什麼便宜虛擬主機 WP 架站的環境,根本不可能開放這種權限。
這種給 AI 用的 CLI 跟以前那種給人類工程師用的 CLI,也需要有不同的設計思維,例如讓 CLI 輸出這種資料
ID Customer Total Status
10293 張XX 1500 Paid
10294 林XX 2800 Shipped
有的甚至還會加上顏色、各種視覺效果,讓命令列操作也能覺得心曠神怡。以前這樣做就很好了,但現在完全不行。
AI 後續如果還要排序、篩選、計算、再接其他流程,上面的資料格式就很容易解析錯誤。
給 AI 用的 CLI 要有不同的設計邏輯,最好能輸出有結構的資料,而且欄位名稱要清楚、有語意,例如:
{
"orders": [
{
"order_id": 10293,
"customer_name_masked": "張**",
"total_amount": 1500,
"currency": "TWD",
"status": "paid"
},
{
"order_id": 10294,
"customer_name_masked": "林**",
"total_amount": 2800,
"currency": "TWD",
"status": "shipped"
}
]
}
錯誤訊息也不能只寫"Invalid argument",應該明確告訴它哪個參數錯、允許哪些值、下一步可以怎麼修正。
AI 不吃工程師之間那些「看一下就知道」的默契,也不吃商業上那套「廠商就是不講清楚,準備好付諮詢費和車馬費吧」,AI Agent 需要的是清楚的參數、穩定的輸出、明確的錯誤、保守的預設值,以及可以追溯的執行紀錄。
要選哪一個? 技術上的考量
技術上來說這不是三選一的問題,而是可以同時存在的。可以做一個 Skills 當上層,讓 AI 去呼叫 MCP 和 CLI。也可以做個本地 MCP,中途有 tool 會呼叫 CLI。但開發量能不足,總要先挑一個效益最高、問題最少的。
講到這邊,大家應該想到最大的問題在哪了:
1.CLI 跟 skills 會有一包檔案,這包檔案可能需要能被主動強制更新,不然一些過時的資料會誤導 AI。
2.需要在使用者的電腦上執行程式。
做出來的 CLI 工具有考慮 Windows 跟 MacOS 系統的差異嗎?
在 skills 資料夾放一些 python 或 php 或 node.js 程式,有考慮過使用者的電腦有沒有安裝執行環境嗎?
如果使用者用的裝置是「你的下一台電腦何必是電腦」,行動裝置 APP 的功能跟電腦上的差異很大,如果 skills 內有一些 CLI, php 程式, python 程式,這根本無法使用,整個流程都要重新規劃。
MCP 的 HTTP 模式幾乎不需要煩惱這些事情,我只需要給一個 URL 和一個 Token 就能用。
要選哪一個? 商業上的考量
當然我知道有些單位特別注重儀式感,最喜歡跑去現場幫客戶安裝、設定、維護,覺得開一個黑黑的終端機視窗,在客人眼中看起來很專業。
然後人力成本很便宜,可以打一整天的電話指導 1 個客人一步一步操作,一票人出門跨縣市一整天就為了幫 1 個客人調整一個參數。做一大堆沒人要看的操作手冊、錄製剪接教學影片。
那一定要選擇 CLI 或 Skills,這樣每次有更新時,還可以找到機會通知客戶,然後重複一次上面的流程。
反觀 MCP 在這點就很爛,貼個網址幾分鐘就設定好,工程師隨時在雲端更新了一堆 tool,使用者也看不出來,對消費者心理和對開發端都是種傷害。
還有一些單位的 AI 商業變現,可能是在自己的系統裡面賣 AI 點數來賺差價,系統裡有一堆 AI 點數、AI 字數、AI 圖片額度、AI 進階方案。使用者每生成一次商品描述、每改寫一次文字、每產生一張圖片,就扣額度,買 AI 點數的帳務系統做得比產品本身還要好用。那本文這種 mcp server 的做法,真是大逆不道。
不同的路線思維,最後會長出完全不同的產品。一個是把使用者鎖在自己後台的 AI 小功能裡爽賺差價,一種是承認現代的專業使用者早就有自己的 AI 工作方式,然後把我的系統變成那個工作流裡最好用、最可靠的一組工具。
當決定要將功能「產品化」或是「開放給一般人用」時,勢必要考慮到使用者的使用習慣和環境限制。
實際開發問題
在實際開發 MCP server 時會遇到很多問題,但也可以從中更了解事物運作的思維邏輯是什麼,而不是幻想 AI 很厲害。
直接把後端的 API 回應包成 MCP Tool 就能用?
有人可能把事情想得很簡單,把本來的程式直接 include 到 MCP Tool 會呼叫的程式中,本來的程式都不用改,只要調整一些接收跟回應的程式,以後就能出一張嘴使喚 AI ,讓 AI 完全代操作網站後台了?
大錯特錯,例如之前的程式可能有後端 API,例如後端回應一包 JSON。
{
"id": 10293,
"st": 2,
"p_type": "A",
"g_id": 50,
"amt": 1500,
"cur": "TWD"
}
前端程式將這些資料處理成 UI,st:2 顯示成一個綠色的 badge,配上各語系的狀態文字,amt 和 cur 組合在一起顯示金額。
要是使用者的 AI 軟體透過 MCP 拿到那包 json,LLM 根本不知道 p_type 和 st 是什麼東西? 因為那些邏輯都在原始網站的程式內。
所以在開發 MCP Tool 或 CLI 腳本中,應該做成類似這種,輸出看似比較有語意的格式:
{
"order_id": 10293,
"status_text": "已出貨",
"product_category": "實體商品",
"group_id": 50,
"amount": 1500,
"currency": "TWD"
}
或者乾脆直接回傳一段可讀的文字:
"訂單 #10293 目前狀態為 [已出貨],總金額為 1500 台幣。"
當然人類交待給 AI 的任務能不能成功,就看使用者的 LLM 能不能理解這些資訊。
搞不好有的 LLM 把上面的資料解讀成這張訂單有 1500 件商品,出貨人員的性別認同(Gender Identity)是 50 號(以 Facebook 的 50 幾種性別來分)。
有些 AI client 軟體只認 OAuth 驗證方式
第一次用 MCP 是在一些 AI coding 工具上(好像在說廢話,畢竟這玩意就是 Anthropic 提出的),設定方式通常是:
- 用 npx add mcp 某某的指令進行安裝,要看 mcp 的官方工具拼湊出自己能用的指令。
- 打開軟體設定,絕對可以看到一眼看到設定 MCP 的地方,這些程式開發工具不會把專有名詞另外改名包裝成什麼「自訂你的 AI 智能體」之類給新手看的名詞。
- 像 Cursor, Windsurf, Antigravity 之類的,就是直接改一個 json 檔案。
- 像 GitHub Copilot 還有一個「MCP 伺服器市集」,有上架在裡面的,滑鼠點一點就裝好了。
這些設定方式都「太工程師」了,那換成一般使用者用的 AI 軟體,要怎麼安裝 MCP?
Perplexity, ChatGPT 等好幾家 AI 軟體,不約而同都把這功能叫做 connector(連接器)。
在 Claude Desktop 中,根本不叫 MCP,要在 Settings>Developer>Edit Config 中設定,然後又要改 JSON 檔案。(claude_desktop_config.json),在 mcpServers 加一組類似這樣的東西
"web-admin-mcp": {
"command": "npx",
"args": [
"mcp-remote",
"https://example.com/XXXXX/mcp",
"--header",
"Authorization: Bearer ${MCP_TOKEN}"
],
"env": {
"MCP_TOKEN": "blahblah"
}
}
到了 ChatGPT 就更麻煩,要先到設定>應用程式,打開開發者模式,然後再去建立應用程式,一打開發現設定介面長這樣子
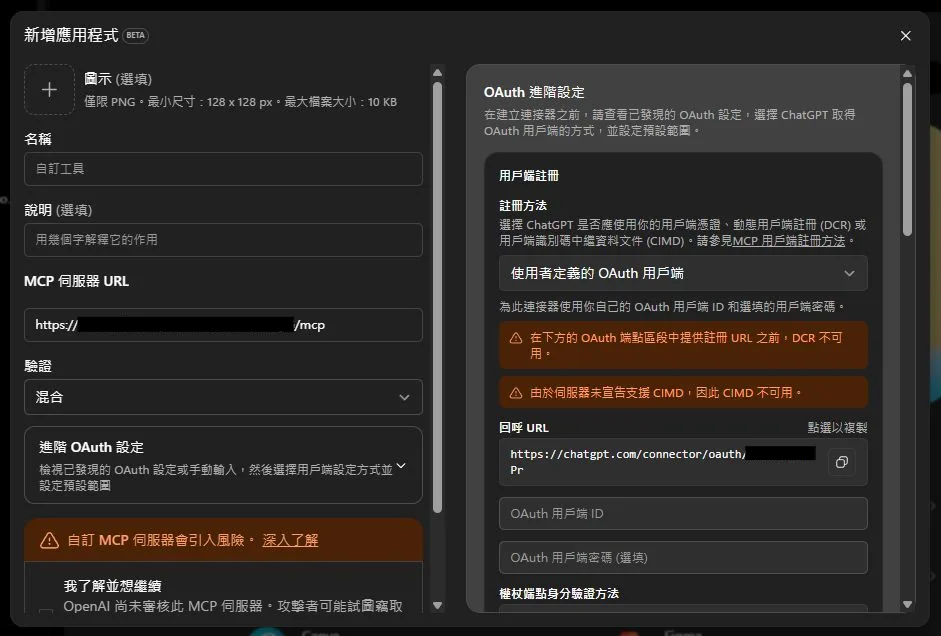
呃...我的 mcp server 一開始是用 Authorization: Bearer 驗證,根本沒設計 OAuth 驗證的流程,不過幸好跟 OpenAI 同一家的 Codex 比較自由,可以設定用 Bearer 驗證的 MCP Server。
論類似撈報表或生成HTML&CSS塞到頁面內的需求,ChatGPT 跟 Codex 幹起活來可能差不了多少,ChatGPT 頂多只會顯示「你已達到 GPT 的使用上限。」一些功能還勉強能用,但是 Codex 左下角有明晃晃的五小時額度和每週額度,額度用完了可是什麼事都不能幹,除非額外加買積分,或是切成 OpenAI API 方案。有的人可能無法接受額度用完就停擺的感覺。
後來又實作了 OAuth 驗證的流程,要多做一大堆用於驗證和各種處理的路由路徑,還要在 .well-known 放一堆東西,資料庫也要多存一堆東西,OAuth 的授權資料必須存在資料庫裡,這個使用授權跟正常的網頁後台是分開的,後台 session 可能關閉瀏覽器就會過期,但給 MCP 用的 session 可不能這樣,不然 ChatGPT 的 MCP 連線會立刻壞掉;但管理員被停用、權限被改掉、token 被撤銷時,MCP 又必須即時生效。
原本單純的權限設計更加複雜,現在變成「有個不是真人的東西拿著還沒過期的 token,能不能授權他操作後台?」
然後御三家的最後一家 Gemini,在連結的應用程式中根本沒得自訂 MCP server,只有 Gemini CLI 或其他產品線才有。
Grok(xAI)的 iPad APP 的 Connector 只能選擇預設的一些,要到網頁版才有自訂 Connector 的按鈕,而且也是 OAuth 驗證。
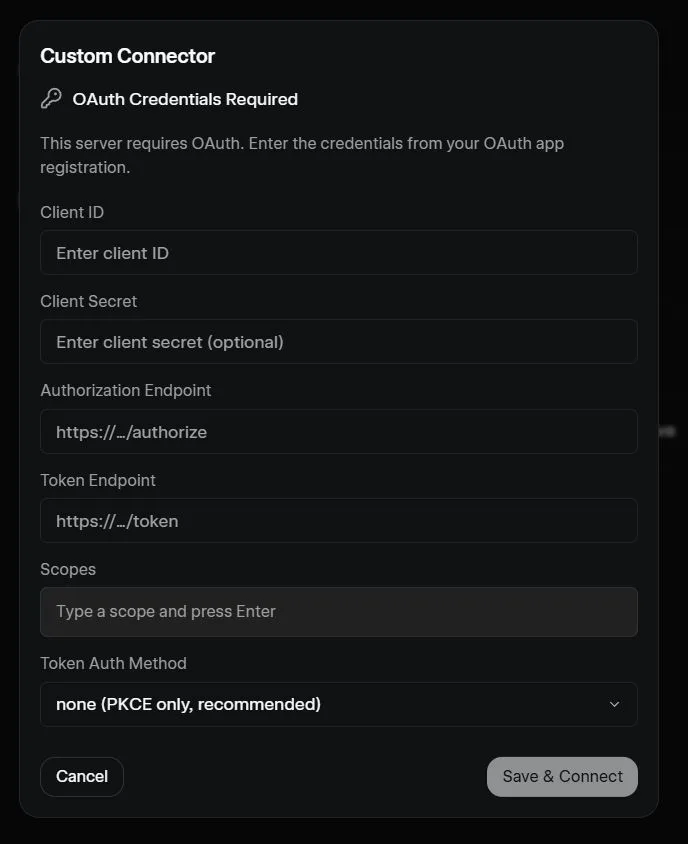
然後像 OpenCode 是要找到 C:\Users\{使用者名稱}\.config\opencode\opencode.json 這個檔案,然後參考官方文件 mcp-servers/#遠端看要怎麼打。
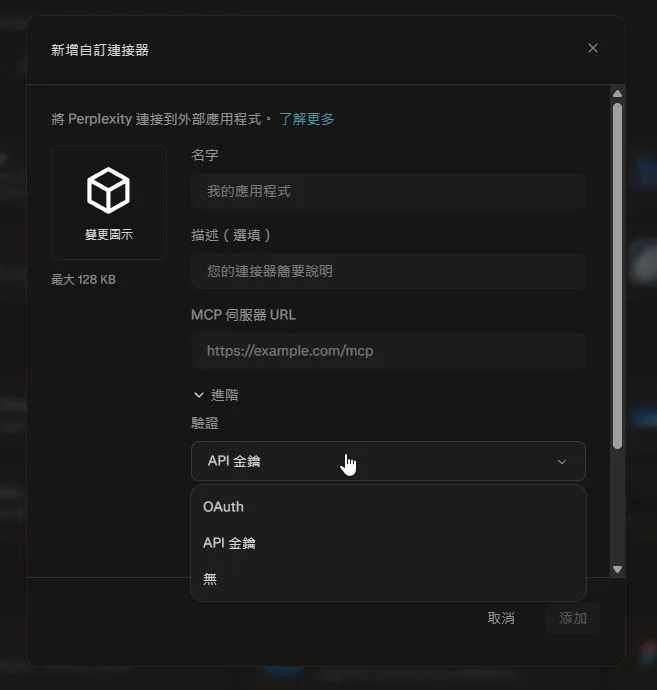
Perplexity 看似在 Connector 提供多種驗證方式,但實際上格式檢查非常嚴格,設定上去有修不完的錯誤訊息Adding Custom Remote Connectors
本以為是自己的問題,然後拿 Meta Ads MCP 或 Ubersuggest MCP 上去試,也是 [API_CLIENTS_ERROR] Dynamic client registration did not return a client_secret 之類的錯誤,留給有緣人使用。
還有一些普通人使用的免費版 AI,根本找不到要如何設定。例如 Monica、Windows Copilot(不是 Copilot Studio) 等等。
再來是一些免費開源模型,tool calling 的能力非常差,有興趣的可以關注 Berkeley Function-Calling Leaderboard。
還有一些二三四線的 AI 軟體,除了聊天對話的基本功能之外,MCP 之類的進階功能要嘛沒做,要嘛 bug 滿天飛,根本沒辦法用。真的不要覺得為什麼免費 AI 這麼多,有人還要花錢去買那幾家 AI。
不是給個清單,AI 就會自己組合資料
一開始設計了一些清單型 tool,例如列出商品資料、列出不含個資的訂單資料。
但是跟串好 MCP 的付費 AI Claude 或 ChatGPT 提問:
「這個月哪個商品賣最好?」
「依照銷售預測,哪些商品可能會即將庫存不足?」
我覺得 AI 可以自動撈出商品資料、
撈出訂單資料,
剔除訂單退貨或未付款什麼的,
然後自動去重、排序、計算。
聰明的 LLM 還會把同一商品的 XXX(五包入)和 XXX(十包入)當成同一個商品來計算。
想像很美好,但實際發生的:
- 很抱歉,目前透過 XXX 的工具,沒有辦法查詢商品銷售排行或歷史訂單明細,工具名稱是什麼?確認後告訴我工具名稱,我可以直接嘗試呼叫看看!
- 呼叫列出訂單的 tool,什麼日期跟訂單狀態條件都沒設(我剛不是說要查本月的嗎?),查了第一頁訂單,隨便胡亂回應一下就結束了。
- 看系統紀錄真的有去撈資料,但是 AI 就直接回應「抱歉,我無法回答這個問題」,因為資料量太大了
- AI 有回應,但完全不對,發現差不多是整理到一半,大概超過推理量或某種系統行數限制,然後就開始胡亂回應。
我還是要再乖乖做一堆 mcp tool,取名 rank_products_by_sales 之類的簡單易懂的好名字,讓 AI 對於熱銷商品、庫存不足、瀏覽數高的商品之類的查詢需求,才真的知道要呼叫哪一個 tool,快速做出回應。
不過 LLM 還有各種特產,例如 lost in the middle, positional bias,都會導致就算 MCP 提供了正確資料,AI 還是回應得亂七八糟。
這邊還有一個 mcp server 設計的問題,就是人類不要多管閒事,有些功能做出來反而會影響 AI 發揮。
例如在 rank_products_by_sales 提供一個 period 的 parameter,而且支援 current_month, last_month 之類的常見時間範圍當參數值傳入,聽起來非常貼心? 實際上是問題非常多。一旦使用者在 AI 問的範圍,超過設計好的那些,AI 有可能發生以下情況:
- AI 回應: XXX 工具的 period 參數只支援 XXXXX,沒有某某某的選項,讓我改用 ZZZZ 工具試試......然後跑去亂用工具,查出亂七八糟的資料。
- AI 自己找一個最接近的時間參數當查詢結果,回應使用者,這樣回應當然是錯的。
還是直接乖乖做日期區間就好了,反正 LLM 會自動根據「上週」「端午節前」之類的生成時間範圍去查詢,人類工程師做 current_month, last_month 之類的功能真是多此一舉。
這些設計經驗是寶貴的,日後還可以用於其他類似的網站新標準,像是 UCP(Universal Commerce Protocol)、Web MCP 。而不會天真地以為,只要把 API endpoint 列出來、把資料庫欄位輸出成一張大表、按照人類的使用習慣去設計功能,AI 就會自然知道怎麼使用我們的網站。
更準確地說,這些經驗會逼我們重新思考:網站不只是把資料從 word/pptx 複製貼上,或是叫 AI 生成一堆頁面就好,而是要讓 AI 看得懂任務、選得對工具、拿得到正確上下文,並在合理限制內完成操作。否則資料給得再多、API 開得再完整,最後也可能只是讓 AI 迷路,然後一本正經地亂用我們的網站。
效能與連線問題
網站可能沒有多少訪客,但只要同時好幾個編輯人員在使用 MCP 更新商品、瘋狂查詢數據、自動檢查並修改站內資料,就可能造成系統負載飆高。
ChatGPT 或 Claude Desktop 等各種 AI client 軟體都有各自的健康檢查機制,從網站 access log 可能會看到那些 mcp 專用的 endpoint,不定時就被自己的 IP 瘋狂連線。然後店家端人員透過 AI 使用 MCP 時,經常瞬間就造成大量 API 請求,有機會一不小心就升高系統負載。
這種現象對於一堆網站放在同一個共享資源的系統環境架構,這不只傷了鄰居的和氣,如果網站還有用到一些按照請求數計費的 serverless 架構或雲端服務,收到帳單肯定爽翻了。但客人會因為這個功能而願意多付錢嗎? 夢話去夢裡面說吧。效能優化有千百條路,但是就看現實讓不讓人走那些路。
所以我又先加了個 rate-limit 機制,限制 mcp 一天只能被呼叫幾次。
但是用量用完後也不能全部封鎖,不然 ChatGPT 或 Claude Desktop 在每次啟動時或中途檢查時,一旦發現 mcp server 無法連線,就會一直跳警告。
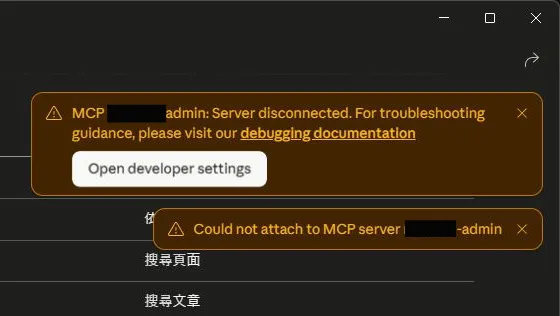
所以還得做成宣告 tool 相關的 method 要能正常通訊,例如 initialize 和 tools/list 要正常接受請求並回應,等到其他真正的 tool 被呼叫時,才跳 429 error 的警告訊息。
做 MCP 才不是讓 AI 直接讀寫資料庫
在前幾點破除了一些迷思,例如開發 MCP 不是把本來的 API 包一層就完事了;不是把資料直接產生一個大清單,AI 就知道要怎麼用。而是要重新思考如何讓 AI 更好地使用這些功能。
那可能有人以為做這種讓店家端用 AI 管理網站的 MCP Server,就是讓 AI 直接讀寫資料庫?
雖然市面上有些工具(如 Chat2DB)標榜讓 AI 生成 SQL 讀寫資料庫,但在網站營運場景中,這是非常危險且低效的。
基本邏輯是使用者端的 AI 根本看不到網站程式碼,不知道資料庫欄位名稱 p1~p12 是拿來幹嘛用的,這件事只有網站自己的程式碼才知道。
例如有些資料是用加密字串存在資料庫的,AI 直接查詢 SQL 只會得到一堆亂碼,只有透過 MCP 呼叫後端,利用現有的解密邏輯,AI 才能拿到可閱讀的資訊。
現代網站常將一些難以正規化、會無限擴充變動的東西,存在單一欄位的 JSON 中。AI 很難精準地寫出 JSON_EXTRACT 或操作特定的 key name 來達成任務。我們必須先把這些複雜性封裝起來,而不是直接讓 AI 亂動 JSON 結構。
本文討論的功能是讓 AI 新增編輯刪除資料,完全視同本人在操作,但是讓 AI 有資料庫刪除權限顯然不是一個好主意,AI 可能因為理解錯任務、選錯 tool、填錯參數、誤判使用者意圖,就把不該刪的資料送進刪除流程,還可能在刪除失敗或回傳訊息不清楚時,自信滿滿地跟使用者說「已經完成」。我們還是讓 AI 操作只能 soft delete 機制的程式就好。
現實是又要幫每個管理帳號發行一組金鑰,然後根據每個金鑰控制不同的使用權限,金鑰還要可以隨時重置,沒有訂單權限的人自然也不能操作訂單相關的 mcp tool,開發成本和維護成本都直線上升。
觀測性問題
當 AI 透過 MCP 執行操作時,我們需要確保這些操作是可追溯的,但這件事比傳統網頁後台麻煩很多。
在人類操作後台時,至少我們大概知道使用者是誰、登入哪個帳號、從哪個頁面點了哪個按鈕、送出了哪個表單。一般系統操作紀錄可能只記錄執行了什麼動作,例如匯出會員資料、修改訂單狀態、幾點幾分用什麼裝置登入,甚至為了節省系統資源,一堆東西實際上都沒紀錄。
即使系統紀錄做得很陽春,access log 裡看到一堆 GET、POST 請求,發生問題時時間點的 URL path,大概還能猜出使用者走了哪些路徑。
但 MCP 不是這樣。
MCP 走的是 JSON-RPC,在 access log 看起來只是一片沒意義的 POST 海。
我無法知道使用者在 ChatGPT、Claude、Cursor 或其他 AI client 裡實際輸入了什麼 prompt。也不知道是真的有人在操作,還是人類設定給 ChatGPT 的排程任務,還是使用者在跟 ChatGPT 聊天時意外觸發 MCP 撈資料。
檢查 access log 內的 User-Agent 字串,也沒有老老實實寫著 ChatGPT、Claude Desktop、Cursor,有些甚至只是一般的 node、Python/3.12 aiohttp/3.13.5、Go-http-client/2.0,或經過其他中轉工具送過來。
這邊的 log 要記錄的東西,又跟傳統的操作 log 不同:
- 我們需要紀錄這是哪一個管理員的金鑰在發出請求
- 紀錄上要能區隔出人類在網頁上操作,還是透過 MCP 操作的。
- MCP log 需要紀錄 AI 呼叫了哪些 tool, param 帶了什麼資料,mcp server 當下執行了什麼,回應了什麼,發生問題時才能快速定位到問題的根源。
更麻煩的是 AI 是不可能背鍋的,例如 mcp server 已經有正確回應資訊
{
"orders": [
{ "total": 5000, "customer": "張**" },
{ "total": 8000, "customer": "林**" },
{ "total": 12000, "customer": "林**" }
]
}
然後 LLM 在回覆給人類時說:「最高消費是張XX的 12,000 元。」
從工程的角度看,資料回傳是正確的。
從使用者角度看,AI 給了錯誤答案。
從產品責任角度看,使用者只會覺得「這個 AI 功能有問題」。
我們不可能像傳統管理方式一樣,把 LLM 叫進辦公室,問他最近怎麼常常出錯?
也不可能把 LLM 的主管叫進辦公室,問他是怎麼管理和訓練底下的人的?
更不可能把 OpenAI、Anthropic 或 Google 的 CEO 叫來給老闆罵。
最後能被叫進辦公室的,通常還是做這套 MCP 程式的人。
紀錄做得不夠完整,MCP 一開始看起來很方便;但只要出一次資料錯亂、錯刪商品、錯改價格、錯發文章,後面就會變成工程師、編輯人員之間的大型甩鍋現場,只有問題源頭的 AI 供應商毫無責任,畢竟已經有免責聲明。
Open AI 的使用條款和 Anthropic 的使用條款都有定義他們的產品叫輸入輸出服務,
You may provide input to the Services (“Input”), and receive output from the Services based on the Input (“Output”). Input and Output are collectively “Content.”
Generally. You may be allowed to interact with our Services in a variety of formats (we call these “Inputs”). Our Services may generate responses (we call these “Outputs”)
然後這些輸入輸出的內容不保證正確性,請自己查證。
本來藏在前端裡的產品邏輯
很多過去由瀏覽器、前端套件和人類視覺判斷完成的事情,一旦要開放給 AI 直接操作,就得在後端重新做一遍。
雖然慘業共識是不要相信瀏覽器傳過來的東西,但有些東西就是這樣做:
- 為了節省系統資源,把資料在前端(使用者的瀏覽器)先處理過,後端只是接收資料,做基本的驗證,然後存起來,而不是前後端各寫一次完整的驗證邏輯和處理邏輯,人類在前端操作時,套件會保證資料結構合法。後端只是存起來。等到要顯示資料時,也只是把那整坨東西直接送給前端套件解析出來。
- 有時候是反過來做,後端只負責吐出所有資料,從前端再做篩選跟顯示排序。有時候是為了視覺上的操作速度,有時候是節省請求數,有時候是後端資料來源那邊沒有要負責處理那些邏輯。
- 在前端壓縮裁切圖片,然後把 base64 字串送到後端處理
- 前端排版套件/流程編輯器/網頁文書工具/地圖編輯器......等各種玩意產生的複雜資料格式。
如果要做 mcp server,有些邏輯就非得在後端重寫一遍了,這在工程上就是一件麻煩事。
另一件麻煩事是本文多次提到 LLM 的不穩定性,如果要讓 AI 直接生成那一坨東西,就算照著 MCP 的各種 instruction 生成 JSON,也很容易在某些細節出錯,而且錯誤可能不是儲存時能立刻發現,而是哪天人類打開編輯器或打開頁面才發現爆掉。
開發 mcp server 需要更加嚴格的資料格式限制
讓 AI 使用 MCP 編輯網站資料,不是天馬行空讓 AI 隨意亂填,仍然是一個蘿蔔一個坑,並且需要更嚴格的坑位限制,還要想辦法引導 AI。畢竟 AI 可以說不幹就不幹,出錯時反覆來回操作,花的也是人類付錢買的 AI 費用。
如果沒有嚴格的資料格式限制,當使用者讓 AI 新增一篇文章,AI 可能什麼都新增了,就是不新增文章。還跑去新增一個頁面,或是使用任何 create/add/new xxx 的 tool 然後胡亂做出操作,然後內容在前後台都無法正常顯示編輯,因為生成了不符合系統格式的資料,AI 還會說「文章已成功更新完畢!」然後這時候使用者又會傳訊息給網站工程師,「我剛剛叫 AI 新增了一篇文章,結果網站後台顯示亂碼,前台頁面也怪怪的。」
tool description 裡要寫好工具介紹
為了避免這種惡夢,在開發這種網站編輯的 mcp server 功能時,首先在每個 tool 的 description 就要寫好工具介紹:
[
'name' => 'create_xx',
'description' => '建立新的XX資料。標題為必填;slug可省略(系統將自動根據標題產生);封面需傳入媒體庫的 media_id;狀態僅限:public (公開), hide (隱藏), member_only (僅限會員)。這是XXX功能,當使用者說要新增一篇XXX/YYY/ZZZ/AAA/BBB/CCC時,請務必使用這個工具,並且按照上述格式提供資料。',
'inputSchema' => [
'type' => 'object',
'properties' => [
'data' => [
'type' => 'object',
'properties' => [
'title' => [
'type' => 'string',
'description' => '資料標題',
'minLength' => 2,
'maxLength' => 50
],
'slug' => [
'type' => 'string',
'description' => '網址代號',
'maxLength' => 30,
'pattern' => '^[a-z0-9\-]+$'
],
'media_id' => ['type' => 'integer', 'description' => '封面圖片 ID'],
'status' => [
'type' => 'string',
'description' => '狀態:public|hide|member_only',
'default' => 'public'
]
],
'required' => ['title'] // 僅強制要求標題
]
],
'required' => ['data']
]
]
然後接下來開始祈禱,AI 看這個這個介紹會知道 media_id 真的會給出數字,不是UUID,不是直接填一串 URL,
祈禱 AI 會自己知道去尋找相關的 tool,
祈禱 AI 能找到列出媒體物件和上傳媒體物件的 tool,
祈禱 AI 正確使用媒體物件的 tool,
祈禱 AI 會自己推理出完成一個任務時,中途可能需要的工具鏈。
inputSchema 裡要寫好資料格式限制
再來可以在 inputSchema 一一補上每個參數的格式限制,例如日期、數字、字串格式是怎樣等等。
AI 的錯誤回應設計要更明確
當然如果資料格式不正確,網站端的系統就會回應錯誤,「傳統程式」的錯誤回應設計可能就是 4xx 或 5xx 錯誤,給個模糊的錯誤訊息,例如內容含有非法字元。但是 AI client 軟體的錯誤回應設計,應該要明確告訴 AI 哪個參數錯了、允許哪些值、下一步可以怎麼修正,這樣 AI 才有機會自我修正。
當然上游資料出錯,AI 還是有可能會瞎掰一些回答來唬爛人類,例如程式已經明確說新增的哪個資料格式不對,AI 還會 thinking 老半天,然後瞎掰說已經新增完成。
強硬的檢查手段或強制變更資料
然後要讓 AI 寫入資料到網站,例如在頁面插入一個聯絡表單、更新商品數量、展示清單等,這些都需要非常嚴格的資料格式限制。否則網站後台編輯介面或前台頁面吃到那些不正確的資料,就會出現奇怪的問題,上面這些規格書 prompt 般的限制,實際上還是常常形同虛設,我們要上一些強硬的手段。
一種是白名單法,例如:
- 把正確的參數通通列出來,例如參數叫 columns_desktop, columns_mobile 之類的,避免生成 perViewDesktop, perViewMobile 之類不存在的 json key 名稱。
- 然後開一個 tool,告知 AI 要做某些操作時,要先呼叫 tool,去查白名單上的可用名稱,
- 在資料儲存時,驗證 AI 是否生成了白名單以外的 json key 名稱,顯示明確的錯誤訊息,祈禱 AI 可以自我修正。
另一種是自動修正法,AI 愛把 block_type 寫成 type,那我們就做幾套正規化程式,會自動把它轉回 block_type。
當然這種規則要做的話,是絕對列舉不完的,最適合拿來整我們基層人員,先決定一種一定會有問題的策略,然後日後出問題,再把第一線執行的人狗幹一頓,非常完美的背鍋流程。
我們不能控制 LLM 到底要生成什麼,只能在生前...生成之前先引導它,並在生成後想辦法修正。白名單法、正規自動修正法,都只能算是一些防線。現實是哪天真的要用到 type 時,可能還要 debug 老半天,為什麼資料都會被自動轉換? 喔,原來是在背後偷偷改了。
以後只要做 MCP 就好?
也許有些工作流程操作非常適合 AI 組合技,例如同時設定了網站編輯的 MCP、SEO 工具的 MCP、文案撰寫的 skills,只要提出一個主題大綱,AI 來幫你完成一連串的任務,這樣效率會比人類一個一個操作來得高。
但並不是所有事務都適合 MCP,有些操作還是傳統的操作中不可取代的。
真的要為了 AI 而 AI 嗎?
如果可以做一個完全沒有 UI 的管理後台,只提供 MCP tool,這樣可行嗎? 當然不可行。
有些操作硬要在 AI 中使用,例如在 ChatGPT 裡面挑選商品照、列印單據? 所有功能都仰賴 ChatGPT/Claude Desktop 能不能把資料顯示成表格、圖片、列表等格式,這都是控制權不在我的事情。
有些資料或報表本來一打開網頁,點一個按鈕就能看到。
但現在變成要使用者在聊天視窗跟 AI 對話、打一大串 prompt,學習跟 AI 對話的技巧,還可能要猜 AI 會怎麼理解自己的 prompt,猜對了才能把資料叫出來,猜錯了就要重新修改 prompt 再問一次。不然 AI 沒有理解日期範圍、有沒有排除特定條件的誤差資料、有沒有把同一商品的不同規格合併、有沒有漏掉某些條件都不知道。
還有些操作在傳統的 UI 上一目了然,例如選了 A 選項後,就有相關的一些選項會出現,一些選項會鎖住,這對使用者是直觀的引導。但是在 AI 中,需要使用者透過發問、對話,AI 才會回答,效率不見得有比較高。
這就像現在一些 AI 工具做圖的困境一樣,花了半小時想把文字往上移一點,某物件右邊留白多一點,在傳統的設計編輯流程,這不就是選中圖層移動一下的事情? 比較新的不一定比較好,挑選最適合的工具才是真的。
然後 mcp server 程式端要製作更多錯誤提示訊息,例如用 1000 字說明哪些選項是互斥的,只能怎樣選才是對的。
他X的,我是在開發 mcp server,
還是在開發 MUD 文字遊戲,
還是在寫密室逃脫遊戲的劇本啊?
還有個隱私性問題,有些極度敏感的操作,在傳統網頁後台 UI 處理時,資料只會存在於「伺服器」與「瀏覽器」之間。一旦改用 MCP,這些資料就必須流經 AI 廠商的伺服器。
為了符合有些行業的資安要求,或是有些單位的內控管理,這類敏感資料任務應禁止開放給 AI,或是做一堆去識別化設計。或是乾脆不要用,以免一有什麼事情,mcp server 或 AI 馬上就要背鍋。
更正一下,無論 LLM 處理資訊時出什麼錯誤,AI 是不會背鍋的,會背鍋的只有做 mcp server 的系統開發人員,和基層的使用者。
以後只做 MCP 就好,完全不用做 API?
講了這麼多 MCP 的好處,可能有人會想,那未來是不是只要做 MCP Server,就不用再做傳統 API (Application Programming Interface,應用程式介面) 了?
當然不是。
MCP 很適合讓 AI 理解和操作系統,尤其是那些原本需要人類在後台點來點去、查資料、整理內容、批次處理、產生草稿的工作。但它不是拿來取代所有系統整合的萬用接口。
例如有些網站資料需要串接 CRM、ERP、POS、會計帳務等系統,甚至是企業內部自己的 BI。這些系統之間的串接,通常需要非常穩定、明確、可預期的資料格式與同步邏輯。
工程師要知道 endpoint 是什麼、欄位格式是什麼、錯誤碼有哪些、多久同步一次、失敗要不要重試、資料版本怎麼控管、webhook 怎麼簽章、資料重複送出時怎麼保持冪等性。
這種時候,跟對方廠商說「這是我們的 MCP 網址,你們叫 AI 自己研究一下怎麼接。」這種大概就跟拿生成式 AI 做的 JPG 圖檔去印刷廠送印,然後跟對方說這是 AI 檔,廠商大概會以為又是來亂的。
系統對系統的整合,是雙方能用穩定規格長期交換資料。不是讓 CRM 每天看心情自己推理一次該怎麼呼叫 tool;也不是讓 ERP 讀取 tool description 後突然領悟訂單狀態邏輯。這些傳統企業系統需要的是正常的 API 規格文件、固定欄位、固定錯誤格式、固定授權方式,以及清楚的除錯機制。
MCP 則比較像是另一層「給 AI 使用的操作介面」。它可以包裝傳統 API,也可以呼叫內部服務,但它的設計目標不是讓另一套系統穩定串資料,而是讓 AI 更容易理解任務、選擇工具、取得上下文,並在權限允許的範圍內執行操作。
所以比較合理的架構不是「MCP 取代 API」,而是:
- 傳統 API:給系統、廠商、APP、前端 這類程式開發串接使用。
- MCP Server:給 AI agent、ChatGPT、Claude、Cursor 這類工具使用。
- 後台 UI:給人類進行可視化操作、確認、審核與例外處理。
很多時候,MCP Server 背後仍然會呼叫既有 API 或 service layer。差別在於,它不應該只是把 API 原封不動包一層,而是要重新整理成 AI 比較容易使用的工具。例如內部 API 可能是 GET /orders?st=2&type=A,但 MCP tool 應該設計成 find_paid_orders_by_date_range、get_customer_purchase_summary、rank_products_by_sales 這種更接近業務意圖的工具。
不要因為 MCP 很新,就幻想它可以一口氣取代所有介面。
當然如果以資本家的世界來說,沒有什麼不可以的,資本家可以不需要什麼 MCP 還是 AI,他只需要有人接案、有人交付、有人在出事時負責。當系統商需要這單生意,不管來源資料格式有多離譜,就算大老闆的系統真的只提供 MCP,市場上一定找得到願意挨打的生意人,硬著頭皮想辦法把它接起來,然後叫做「客製化整合解決方案」。
MCP 可能讓後台更簡單,但不一定讓系統更簡單
對系統開發而言,殘酷的現實是維護成本的倍增。一旦決定擁抱 MCP,等於專案程式碼中從此多了一個平行宇宙。
未來只要網站核心功能一改版、資料庫結構一調整,不只要改網站前後台的前後端程式,還要額外去照顧那一套 MCP Server 的程式碼。
而且設計 MCP Tool 的邏輯跟寫一般 Web App 完全是兩回事。寫一般網頁後台一個要點是「防呆」(防範人類的不小心與亂點),但寫 MCP 是「防幻覺」(防範一個自作聰明、極度自信、還會自己腦補欄位格式的超級大腦)。我要教 AI 怎麼分步驟拿資料、怎麼在報錯時自我修正,這兩者的防禦機制、錯誤提示設計,甚至是效能考量,完全不在同一個維度。
普通網頁後台,背後偷改欄位、改流程,使用者可能根本不會發現,改 UI,最多是使用者重新適應。
但要是 MCP 亂改 tool 名稱、改 schema、改回傳格式,可能會讓使用者原本在 ChatGPT、Claude 裡設定好的工作流失效。
甚至 AI 之前學會的操作模式,也會因為 tool description 或 schema 變動而變不穩。
一堆功能要重新設計,把複雜度從人類可見的 UI 搬到 AI 可操作的標準協議,這本身就是一個工程。工程化問題很累,但做這種「看不到的東西」,通常是沒辦法成為有功的猴子的。
結語
說到底,搞了這麼多 MCP、Skills,有時候退一步看,真的會懷疑是不是一場工程師跟資訊慘業的自嗨與技術噱頭?
我們好像已經走到 AI Agent、自動化工作流、MCP 跟 Skills 滿天飛的時代,但走到第一線,
可能還是公司一堆人共用一個帳號,
註冊一堆帳號薅羊毛用免費額度,
使用 Google 企業信箱或微軟 Office 365 裡面「附贈」的 AI,
在聊天跟多個分頁裡複製貼上、上傳文書檔案、叫 AI 幫忙想一段文字、整理表格。
把 AI 深度整合進系統,絕對是個迷人的技術挑戰,確實能在某些情境下摧毀傳統系統 UI「資料篩選條件爆炸」之類的痛點。
但如果在投入開發前,沒有想清楚客群有沒有對應的數位素養,或是團隊沒有量能去扛下另一套系統的維護與 SRE 災難,那真的不要「為了 AI 而 AI」。
畢竟,比起一個動不動因為 LLM 格式出錯或而無法操作的高級 MCP,使用者可能還是覺得那個在聊天視窗裡剪剪貼貼的自己,更有掌控感跟安全感吧。
小型店家反而更適合 MCP?
聽到層出不窮的技術名詞,很容易以為這又是大公司、有工程團隊、有資訊部門才玩得起的東西。但實際做下去後,我反而覺得,小型店家可能才是最容易感受到 MCP 價值的人。
原因很簡單,小型店家的人力槓桿太嚴重。一個人可能同時要當美編設計、客服、社群小編、行銷企劃、商品上架人員、網站管理員、倉管出貨、資料分析師、業務銷售員,本來就已經大量使用各種生成式 AI:寫商品描述、改活動文案、想社群貼文、生成留言回覆、整理 FAQ、產生 SEO 標題,最後再把內容複製貼上回各種網站後台。
現在網站後台多了 MCP 功能串接 AI,讓原本已經在 ChatGPT 裡完成的工作,不必再靠人工搬運。以前是「叫 ChatGPT 寫好,再自己貼回後台」;現在可以變成「在 ChatGPT 裡整理好內容,直接建立文章草稿、更新商品描述、調整頁面區塊」。對小型店家來說,這是少開幾個分頁、少貼錯幾次欄位、少浪費半小時的實際差異。
反而大型公司未必適合這種高度自由的 MCP 操作。(理論中的)大公司有專門的行銷、設計、編輯、工程,每次發文或改活動頁,都要做幾張 PPT,經過法務與主管審核流程,根本不可能有一個人用自己的 ChatGPT 直接改正式網站資料這種事發生。
對大型組織來說,MCP 比較可能被設計成內部受控的草稿產生器、資料唯讀的查詢工具、審核流程入口,而不是讓 AI 「直接去打方向盤」。
所以這種工作流程的適用對象,是決策路徑越短、角色越混合、越常依賴 ChatGPT 這種工具完成日常工作的團隊,越容易感受到 MCP 的價值。