
豆包和掘金的 AI 生成垃圾,對中文 SEO 搜尋結果的影響
想像一下,如果有一個服務把大家跟 AI 的線上對話紀錄,挑選整理後,公開放到網路上讓搜尋引擎來抓。
又或者有一個投稿平台把大家的文章進行 AI 訓練後,使用生成式 AI 自產自銷文章,這兩種都是為了得到更多流量。
這不需要想像,也不需要如果電話亭,這個是已經發生的事。
豆包 AI 助手的 SEO 之亂
豆包是一個 AI 智能助手,由字節跳動的子公司,北京春田知韵科技有限公司所開發。
豆包的 AI 是基於雲雀(Skylark)大模型開發,雲雀模型是字節跳動公司的自研大模型。
嗯,可以把豆包簡單理解成抖音集團出的 ChatGPT 吧。
豆包在 2023/8 開始測試,在本月 2024/5 月中發布了要進行付費商業化的消息。
而在近期豆包又開啟了一波騷操作,隨便使用中文搜尋都可以見到類似這種內容:
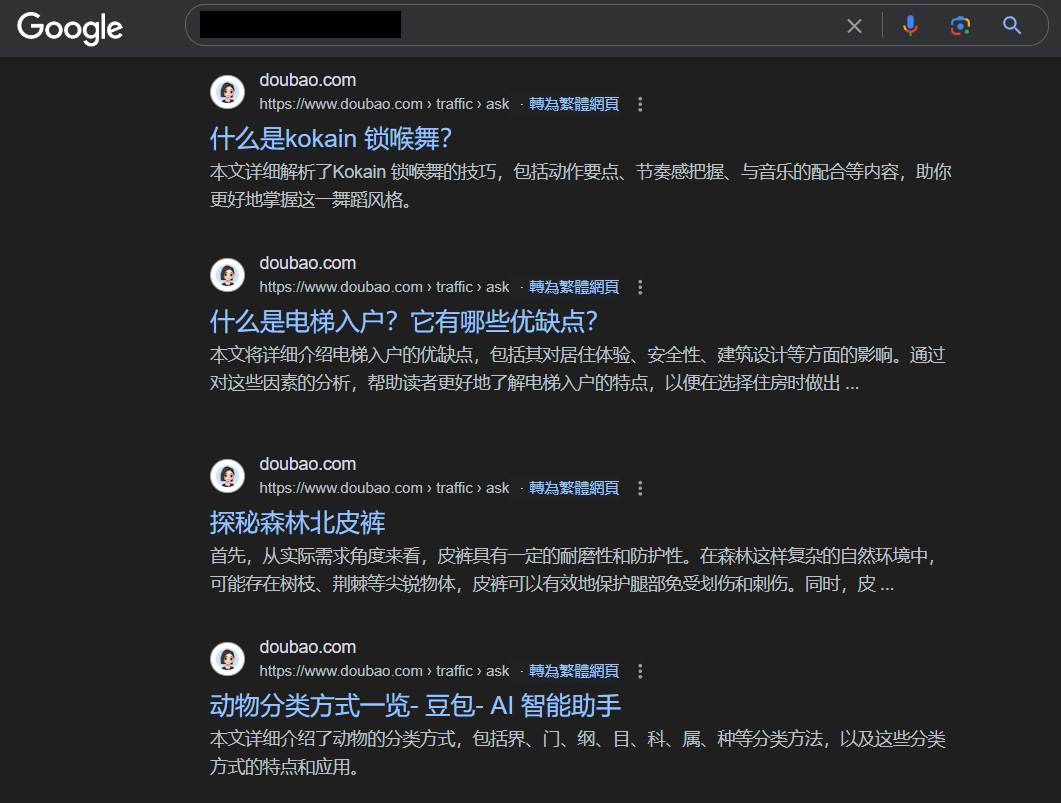
使用 site:doubao.com/traffic,可以查到這些頁面在 Google 上的搜尋結果數量,最多時超過 2000 萬筆,有些還排上了精選摘要。
使用者看到這些搜尋結果,點進去可以看到內容,得到解答嗎?
不。只會看到一開始的豆包 AI 歡迎畫面。
這波操作不只影響到不少中文的 Google 搜尋結果,更有一些網友發現結合了搜尋引擎與聊天機器人服務的 Perplexity,也會在搜尋結果中出現豆包。造成 AI 生成的內容來源,是別的 AI 生成出來的,未來的世界就靠 AI 自產自銷、互相汙染,就沒有人類的事了。
為了流量與產品增長,無所不用其極,這波操作真是老鐵 666 啊!
在 2023/5/31 時,有人說字節跳動已將豆包的這個 SEO 汙染功能下線。
掘金的 AI 助手生成文章之亂
掘金(全名稀土掘金)在 2014 年成立,是一個主要面向網路產業技能的的內容分享平台。在 2020 年時,掘金背後的北京北比信息技術有限公司,被字節跳動收購,成為字節跳動其中一個的全資子公司。
抖音! 又是你!
如果使用中文搜尋程式開發、網頁前後端、APP 開發相關的內容,可能偶爾會找到掘金上面的文章。畢竟中文的技術社群就那些,有些東西用英文基本又找不到什麼有用的內容。
當然掘金也有不少爭議發生,例如時不時有台灣開發者在「牆外」發表的文章,被「漢化」後「搬運」到掘金上面去,而完全不附出處。
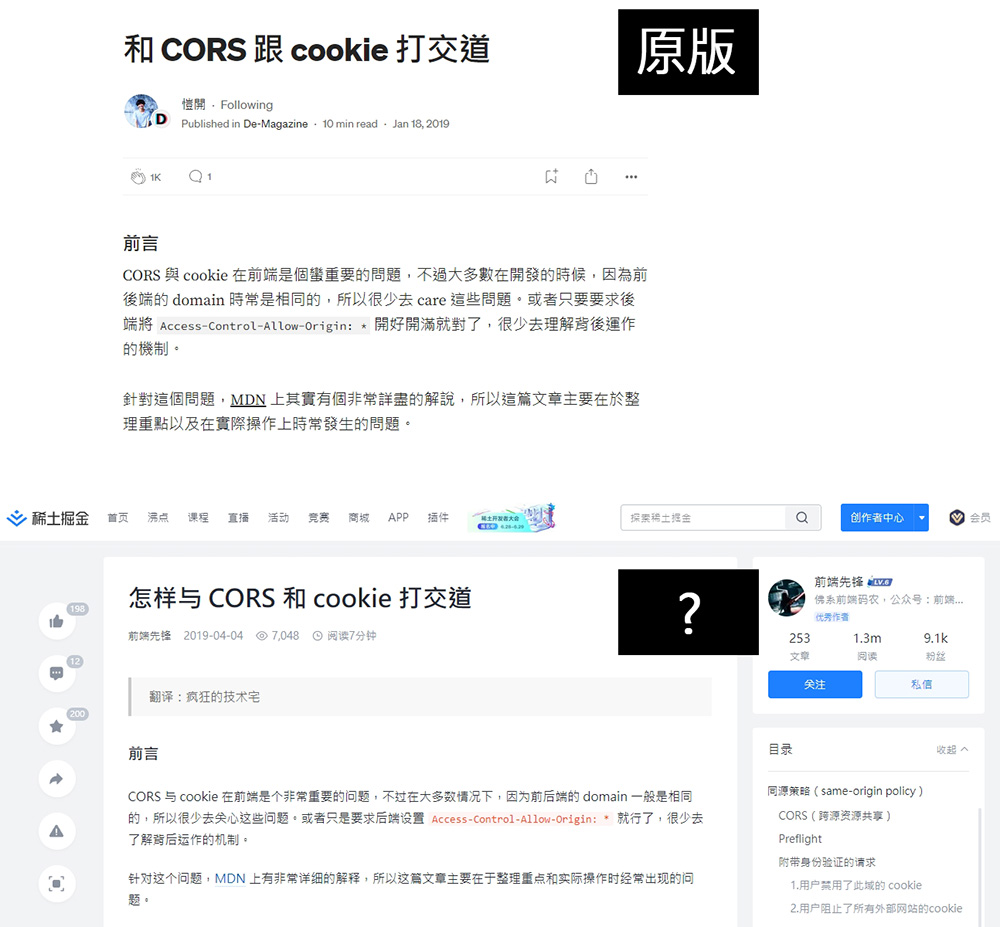
在這幾個月,不少對岸網友更發現,在上網搜尋資料時,會找到網址結構像這樣 juejin.cn/s/* 的頁面,頁面底下有一行字:
本内容由 AI 助手生成,请问对您是否有帮助
可能因為這是技術員聚集的社區,比較重視大家的意見。
最後平台在 2024/5/30 的時候宣布,將 AI 生成用於 SEO 的內容移除了。過一陣子 Google 就不會看到 AI 生成的掘金文章。
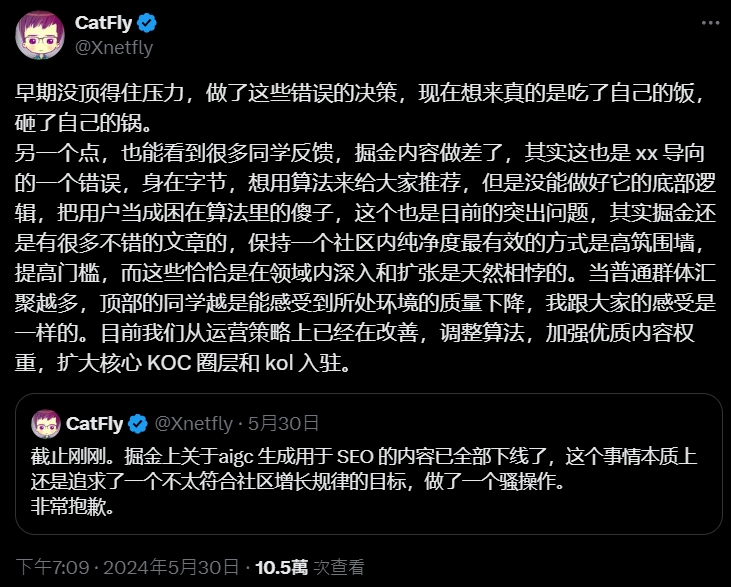
早期没顶得住压力,做了这些错误的决策,现在想来真的是吃了自己的饭,砸了自己的锅。
另一个点,也能看到很多同学反馈,掘金内容做差了,其实这也是 xx 导向的一个错误,身在字节,想用算法来给大家推荐,但是没能做好它的底部逻辑,把用户当成困在算法里的傻子,这个也是目前的突出问题,其实掘金还是有很多不错的文章的,保持一个社区内纯净度最有效的方式是高筑围墙,提高门槛,而这些恰恰是在领域内深入和扩张是天然相悖的。当普通群体汇聚越多,顶部的同学越是能感受到所处环境的质量下降,我跟大家的感受是一样的。目前我们从运营策略上已经在改善,调整算法,加强优质内容权重,扩大核心 KOC 圈层和 kol 入驻。
推文連結(發推文的人是掘金的運營經理)
當然掘金在追求增長的時候,還保有一絲道德底線,至少從 Google 點進去,還真的能看到要找的內容,也有 AI 生成的標註。
其他阿里雲、騰訊雲的騷操作更是令人不敢恭維,讓人在 Google 以為找到答案了,結果點進去是這種東西…
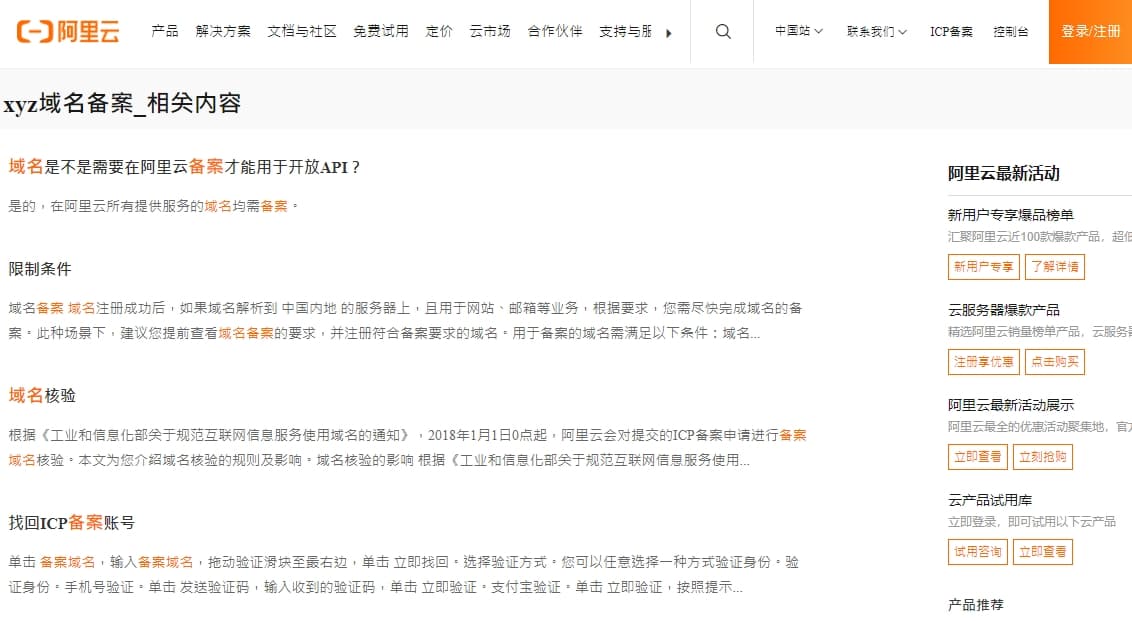
site:aliyun.com/sswd
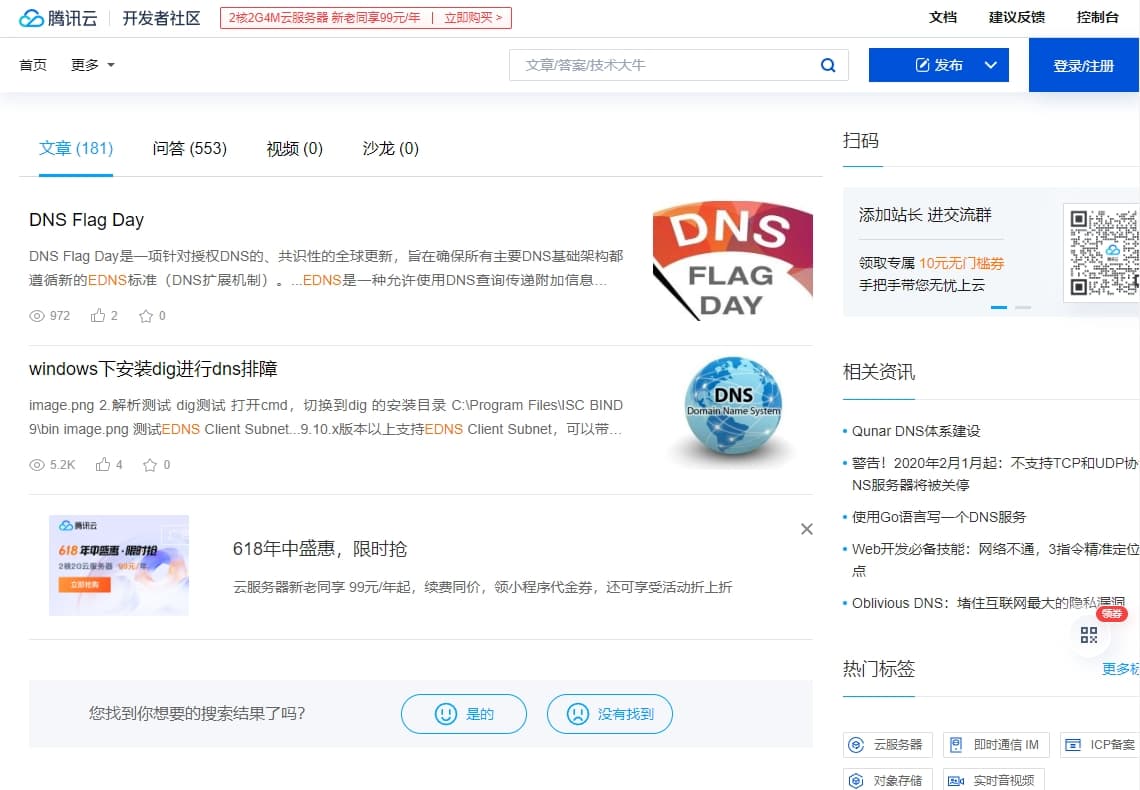
site:tencent.com/developer/information
其他由生成式 AI 幫平台產生頁面的類似服務
對此,五星上將麥克阿瑟表示,其他線上服務同樣也有很多使用者,同樣也都是仰賴使用者生產內容(UGC),難道別人都想不到嗎?
其實平台用生成式 AI 來增加內容用於 SEO,還真的有類似的。
LinkedIn Pulse
例如 Linkedin 有一個協作文章,會由平台發起議題,並邀請專家來做出內容貢獻。
每一篇文章開頭都掛著大大的:
由 AI 及 LinkedIn 社群提供支援
平台端可能利用生成式 AI 來選題,然後邀請各路人類專家上去當素材產生器。
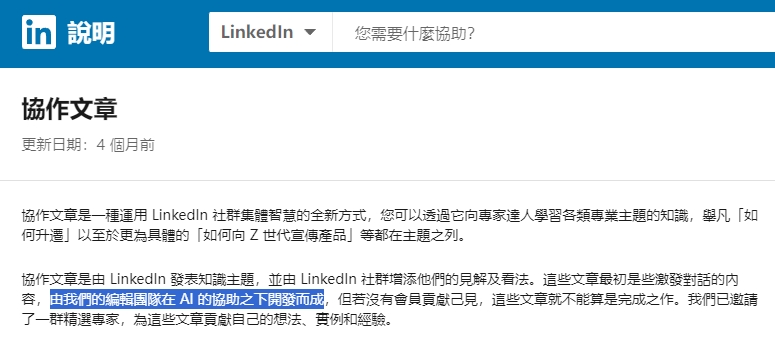
協作文章是由 LinkedIn 發表知識主題,並由 LinkedIn 社群增添他們的見解及看法。這些文章最初是些激發對話的內容,由我們的編輯團隊在 AI 的協助之下開發而成,但若沒有會員貢獻己見,這些文章就不能算是完成之作。我們已邀請了一群精選專家,為這些文章貢獻自己的想法、實例和經驗。
LinkedIn 說明 – 協作文章
Perplexity Page
Perplexity 也在近期 2024/5/30 發布 Perplexity Pages的功能,大致就是使用者可以把搜尋與生成的內容製作成公開頁面,而且搜尋引擎也能搜尋到。
以後看到網址是 https://www.perplexity.ai/page/*開頭的(如下圖),就是使用者用這個功能產生的。
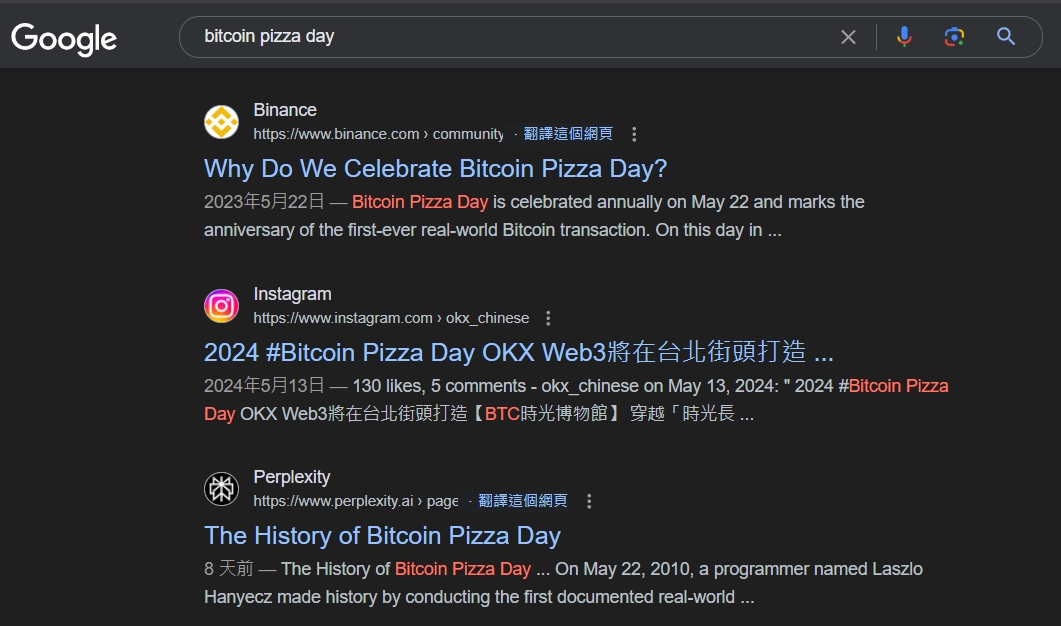
這功能目前需要 Perplexity 的 Pro 方案用戶才能使用。
產品概念也許很有趣,但也有人吐槽把一些 LLM 生成,未經驗證的資料,湊合成一個頁面,號稱叫 AI 維基百科? 簡直是荒謬。
不過罵歸罵,功能上線沒幾天,有些 SEO 專家用 Ahrefs 查詢,已經有不少 Perplexity Page 在 Google 搜尋都有不錯的排名。
後續也傳出更多神奇用法,例如假裝詢問 AI 關於自家產品的內容,然後利用 Perplexity Page 幫自己家的產品做一個頁面,在搜尋引擎卡位。
觀察一些 Perplexity Page 頁面上的連結,目前還沒有標 nofollow,所以會被搜尋引擎當成外部連結。有標 noreferrer,所以如果有人從 Perplexity Page 點擊到自家網站,標頭的 referrer 不會帶過來,GA 不會顯示來源是 Perplexity Page。
ChatGPT Shared Links
ChatGPT 同樣也有一個將對話產生分享連結的功能,雖然在官方的功能說明ChatGPT Shared Links FAQ中有寫到:
Should we expect shared links to show up in public search results on the Internet?
No, shared links are not designed to show up in public search results on the internet. They are intended for direct sharing between individuals and are not indexed by search engines. However, anyone with the link can view the shared content.
(我們應該預期分享連結出現在網際網路的公開搜尋結果中嗎?
不,分享連結並不是設計用於出現在網際網路的公開搜尋結果中。它們旨在供個人之間直接分享,不會被搜尋引擎索引。然而,任何擁有該連擷的人都可以查看共享內容。)
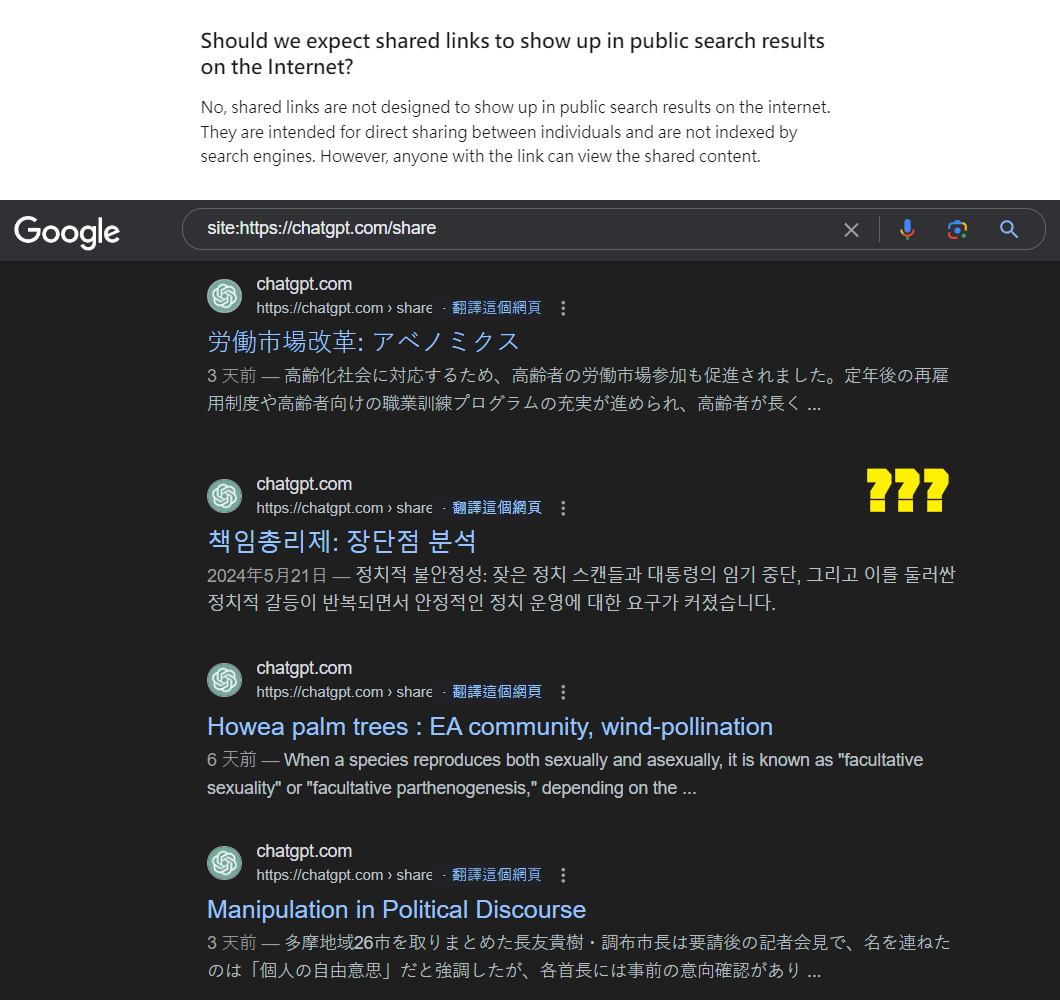
但實際上用 site:https://chatgpt.com/share 還是可以找到一些分享對話內容的頁面,看起來只是不會主動提交,但頁面沒有設定 noindex 禁止索引。
同樣的邏輯,Poe 也是可以分享對話,分享出來的網址開頭格式會是 https://poe.com/s/ ,但在搜尋引擎上能找到的不多。
而且 Poe 的分享對話設計比較不同,預設只會分享最後的一問一答,其他的要自己再勾選,跟 ChatGPT 一次分享就是一整串不一樣。
心得感想
1.台灣的平台也會這樣抄嗎?
可能還暫時不用擔心方格子、痞客邦之類的這樣搞,例如平台直接拿好幾個人寫的餐廳旅遊食記文,用 AI 組合成一篇新文章,但食物照片總不能用假的吧? 勢必還是會用到原文的照片。
也許還有其他方法可以繞過,但是「創作者平台」跟平台用戶(網紅/部落客)搶流量聽起來還是有點奇怪。
反而是一些平台本身就是某些領域的知名入口網站,平台人員本身也有領域 knowhow,這種平台想要「跳過作者」,用 AI 生成內容來爭取更好的 SEO 排名和流量,聽起來倒是很合理。
2.狼性文化
稍微看得出來,其他平台的功能,可能沒有抖音集團這麼有狼性。
平台端不會主動產生新內容,就算平台端主動產生新內容,也是為了給使用者創作空間,而不是為了騙 SEO 流量,讓外面的人點進來但什麼都找不到。
使用者還是擁有一些控制權,自己決定要不要去參與、操作那些功能。而不是使用者同意 EULA 就像簽了賣身契,使用了平台功能之後,所有資料都變成人柱力。
3.使用者可以怎麼辦
對於這種大量生成內容,網站企圖用 SEO 技巧汙染搜尋引擎,使用者點進去卻看到劣質內容的行為,上街遊行也沒辦法解決問題。

民間自救手法頂多是使用者自已用一些瀏覽器套件,封鎖某些域名的來源。或是嘗試填寫 Google 的檢舉表單。
要完全根治,只能看商人的良心,或是等待搜尋引擎出手過濾了。
4.流量下跌的戰犯?
對於一些搜尋引擎來源流量減少的中文網站,可憐的 SEO 勞工們可能還在苦惱要抓誰來當戰犯,
是 Google 搜尋的 March 2024 spam update 演算法更新?
是大家都直接跟 AI 聊天,不上網找資料了?
搞不好可以藉機把問題推給掘金和豆包,省下查報表跟研究競品的時間。
5.平台方的角度
如果我們換個角度,以平台經營方的角度來看,因為產業快速迭代,大家留在平台上的技術寫作文章,部分內容難免會過時,作者又疏於維護,免不了讓讀者有「平台上面都是一些過時的文章」「平台都不管喔?」的不良觀感。
如果這時候如果平台和編輯人員用生成式 AI,能把這些過時的內容更新,甚至把多篇內容湊合起來,重新寫一篇,這樣有違創作倫理或法律權利嗎? 這又是個有趣的議題。
當然這有時候跟行業別有關,就算新的 AI 大拼盤內容寫得再好,上面沒有掛個作者、機構名字來背書,沒有人敢信服,也無法在正經的用途上當作參考資料。
6.中國好生意
一開始不曉得出現在 Google 搜尋結果裡的「豆包」是什麼,但多虧一些中國人民有爬梯子、翻牆出來,使用 Twitter(X)、ChatGPT、Google 這種在中國境內網路禁止使用的一些海外線上服務,在上面討論與分享,才讓我們這些外國人知道對岸有這麼刺激的玩法。不然可能還要註冊微博,整天刷微信公眾號、在各大社區蹲守爬文,才知道發生了什麼事。
還有其他的奇聞像是:
2024 年 APP 備案新制
在中國上架 APP 也要向政府備案,一般海外企業根本沒辦法沒辦法執行,導致在 App Store 搜尋只會找到一堆假的 APP。
對岸自己的 AI 大模型生態系
談到要製作一些生成式 AI 線上服務,串接生成式 AI 的 API,我們關心的是 OpenAI 又降價,三大公有雲上面可以直接申請、PCHome 上面有賣 H100 之類的。
但中國境內面對美國持續要求業者不得出口AI晶片至中國的禁令,也無法直接使用我們常見的 OpenAI API、ChatGPT、Google Gemini、Claude 之類的。生命自己找到出路,對岸倒是則是有一堆套殼來賣的,或是一堆國內自研的大模型,關心的是 Deepseek、智譜、科大訊飛、文心一言的 API 要怎麼計費,完全是不同世界。
国务院《计算机信息网络国际联网管理暂行规定》第6条:任何单位和个人不得自行建立或者使用其他信道进行国际联网。
再次呼籲,翻牆行為不僅違反了中國的相關法律法規,也可能幫助傳播引起社會混亂的訊息。
延伸閱讀
- 百度百科 – 豆包
- 豆包的一场SEO,让AI搜索成了”内容垃圾场”
- 幽默掘金,用 AI 生成了 2560 万 个垃圾网页,还被幽默谷歌标记为精选, AI 时代确实来临了 – V2EX 文末還有放上阿里雲、騰訊雲、火山引擎也在做這種做垃圾頁面騙 SEO 流量的網址。
- 豆包正式加入 SEO 污染大家族 這篇推文舉了一些被豆包卡位,甚至上精選摘要的 Google 關鍵字的搜尋結果擷圖。
- 独家专访 | 稀土掘金90后创始人阴明:最新融资2000万、估值1.3亿背后的技术社区 2017 年的專訪,現在看可能有點令人唏噓…
- ChatGPT bug leaked users’ conversation histories – BBC ChatGPT 曾經在 2023/3 發生一個 bug,在自己的對話紀錄內,會顯示別人的對話紀錄,官方很快修復這個問題。跟本文中豆包的案例完全是兩回事。
- 用户可以贡献topic idea,帮助perplexity生成无限多的pages了 使用 Ahrefs 查詢 Perplexity page 在哪些關鍵字的排名很高。
- 廣告變AI引用內容 中國官媒批GEO軟體投餵假資料 捏造了一款名為Apollo-9的智慧手環,編造虛假用戶評價,並自動生成10幾篇推廣文章發布到自媒體。僅兩個小時後,AI大模型竟引用這些虛構內容,推薦該手環,並給出購買建議。